I’m struggling to get back into my motivated groove for Extended Stats since all the holiday stuff. Although my wife is away and hence is unable to distract me, the dog is not and she demands an inordinate amount of attention. I’m also doing a lot of cooking of things that I can’t make for my vegetarian wife. This evening’s nasi goreng was pretty good if I do say so myself. But not much coding got done.
Today’s project was the top-right sticky note, which says “Express & EB”. Express is node.js software for writing a web server, and EB is Elastic Beanstalk, an AWS technology for scaling web servers – essentially you tell it “Here’s my code, put it on a machine. If it gets busy start some more machines running the same code.” I use EB at work, but I’ve never used Express before.
I’ve been getting the feeling that AWS Lambda is a little expensive for some of the things I want to use it for. In particular, the note below “Express & EB” which says “geek buddies”. The plan for that note is that if you’re logged in you’ll be able to tell the site which other users are in your game group / family / other peer group. And the plan for that involves an autocomplete field where you start typing a BGG user’s name, and I give you all the valid completions for what you’re typing.
That’s easy enough to code, but it usually involves one HTTP call for each character typed, and as I pay for each HTTP call to a Lambda, I’m not very keen on that. So the plan is to make an Express server which can handle very tiny calls like that for a pretty much flat rate of a couple of bucks a month. That should decrease my Lambda costs (which I should also write a post about).
However, today’s plan to run Express on Elastic Beanstalk foundered at the bit where I tell Elastic Beanstalk about the database. Omigod, AWS security is basically impenetrable twaddle. At least, it is to me. At work we tell the servers about the database a different way which I don’t want to use here, so I would like to configure the database in EB. I ended up with EB and the database both in virtual private clouds, but in different virtual private clouds. Is that good? I don’t know. It was like when you can’t find two socks the same colour. So in the end I got cranky and dumped the EBs and will try to do some reading so I can get half a clue for the next attempt.
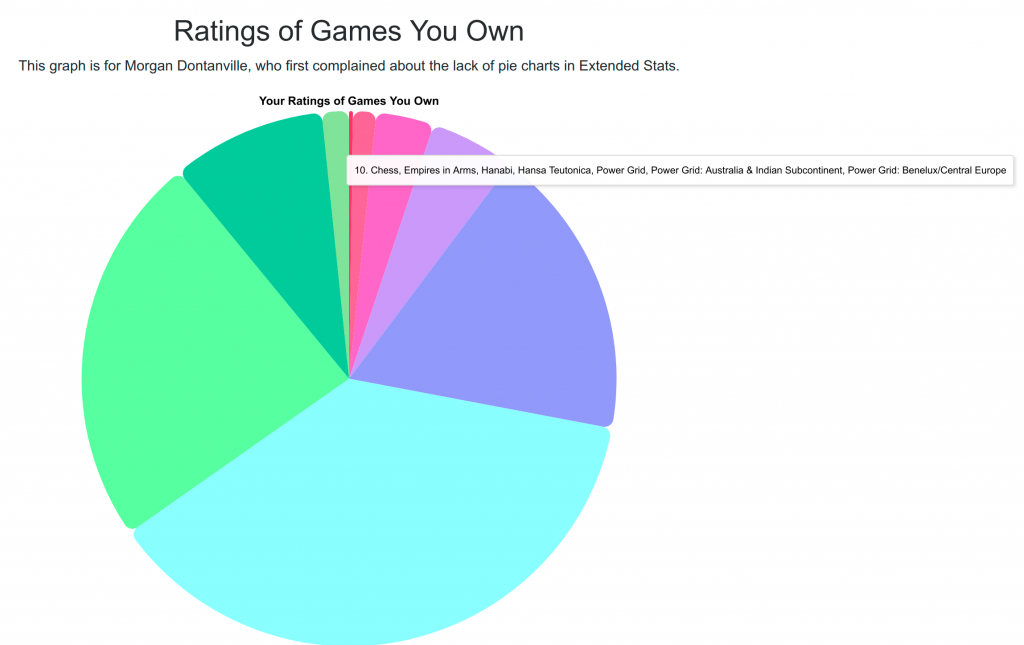
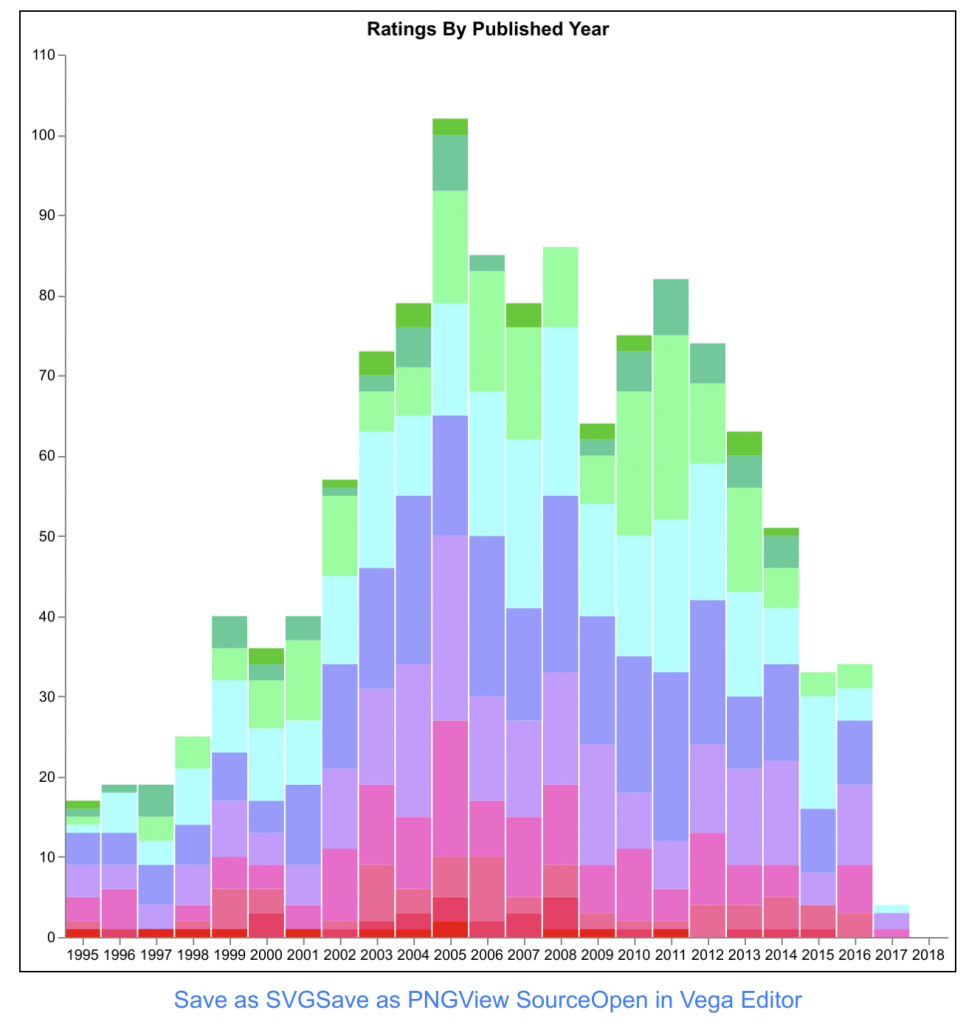
In happier news, I did manage to fix a big. BGG started sending my ratings for games people hadn’t rated is “N/A” instead of just completely absent, so I was trying to store “N/A” as a number which broke stuff. Thanks to a new user for pointing out to me that something was broken.
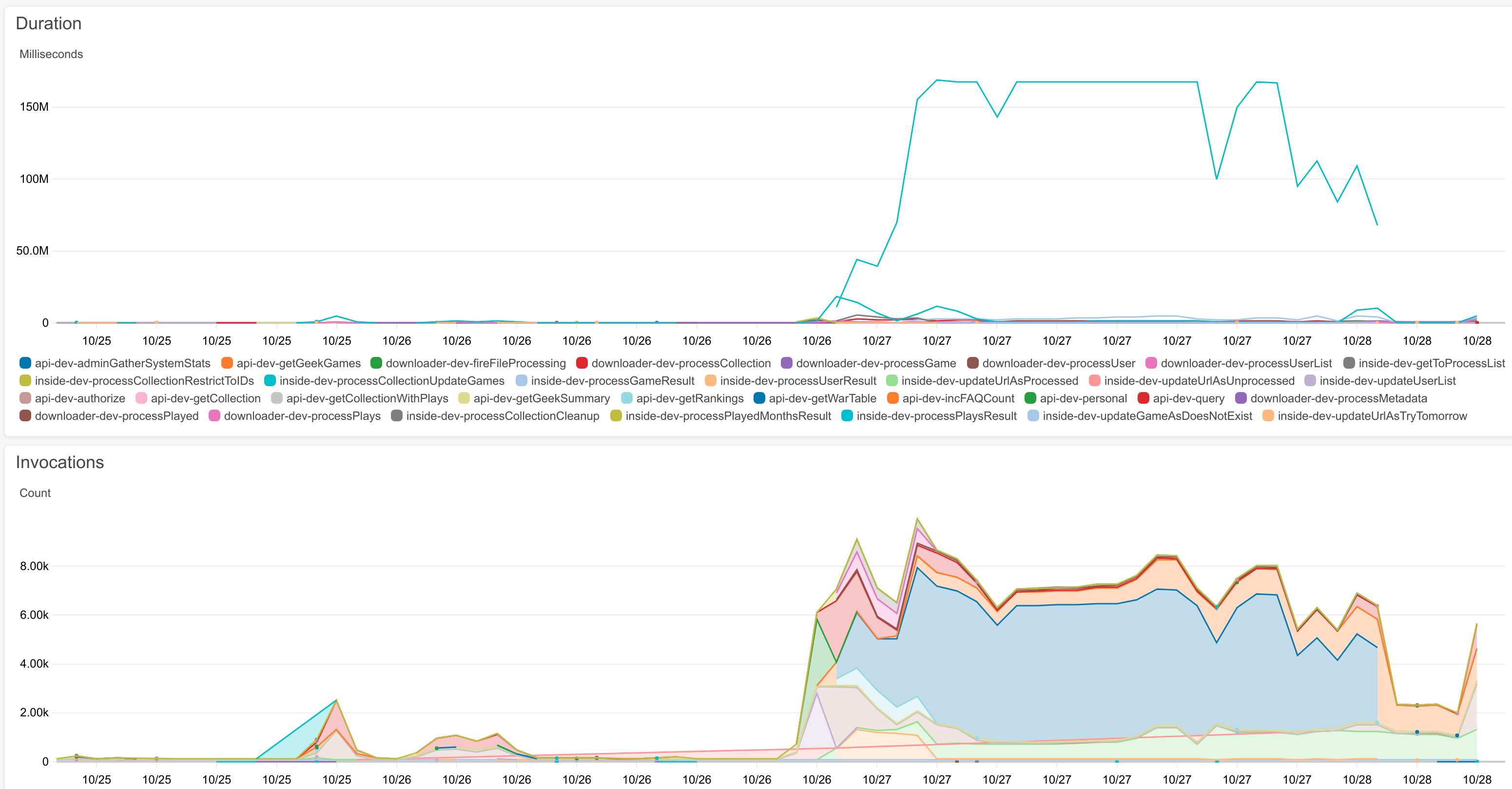
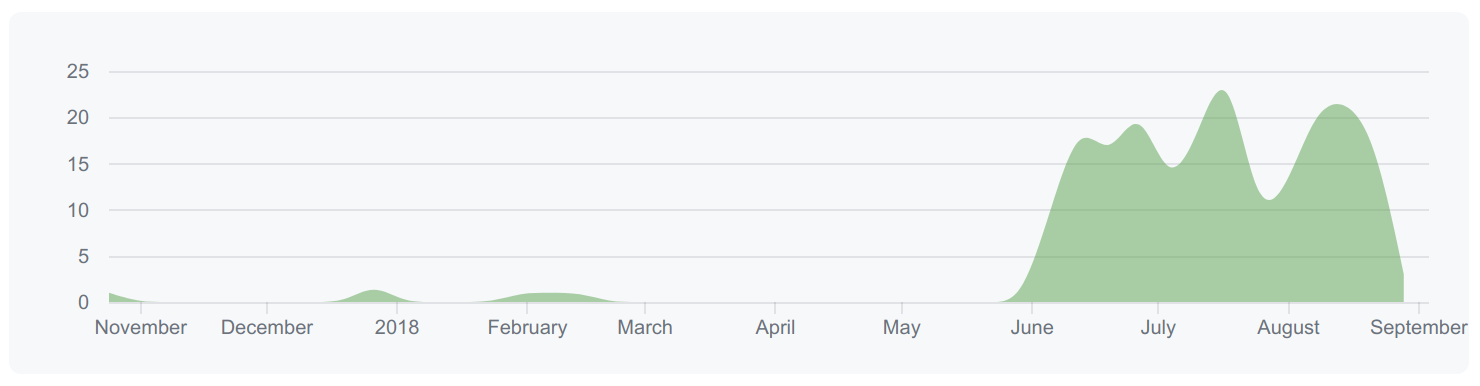
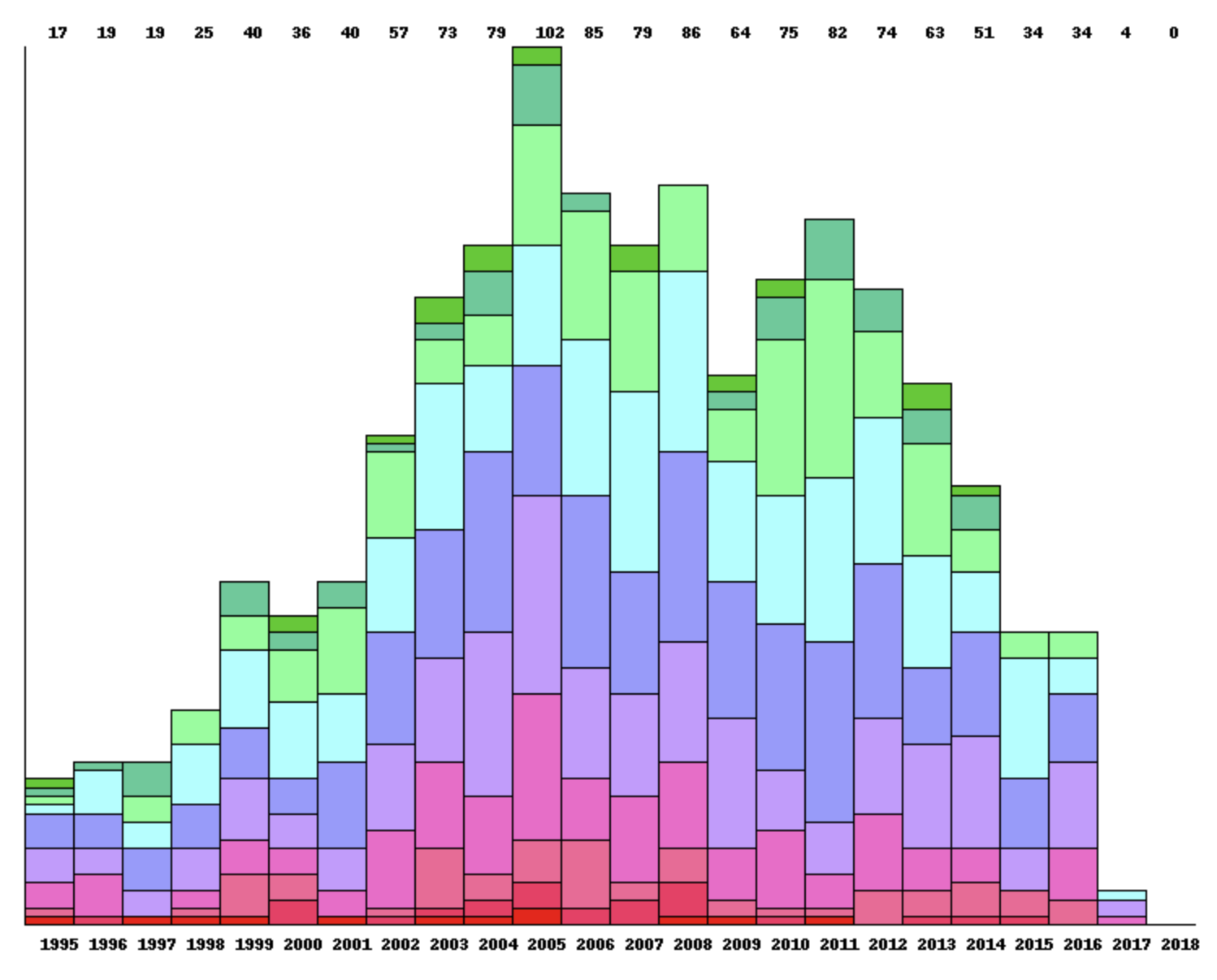
The next bug I found was that if you have many many plays in a month, for example 3750, BGG tells me to stop asking for so many files all the time. As the Lambda wants to get its job done quickly because I’m being billed for the time it runs for, I can’t just sit around and do nothing. So I need to come up with a plan for dealing with many pages of plays over several lambda invocations. Something nice-ish will spring to mind eventually, I suppose. That technique could possibly also be adapted for users with very large (BGG) collections, e.g. 100000 as I have seen. Where’s my thinking cap? I need my thinking cap.