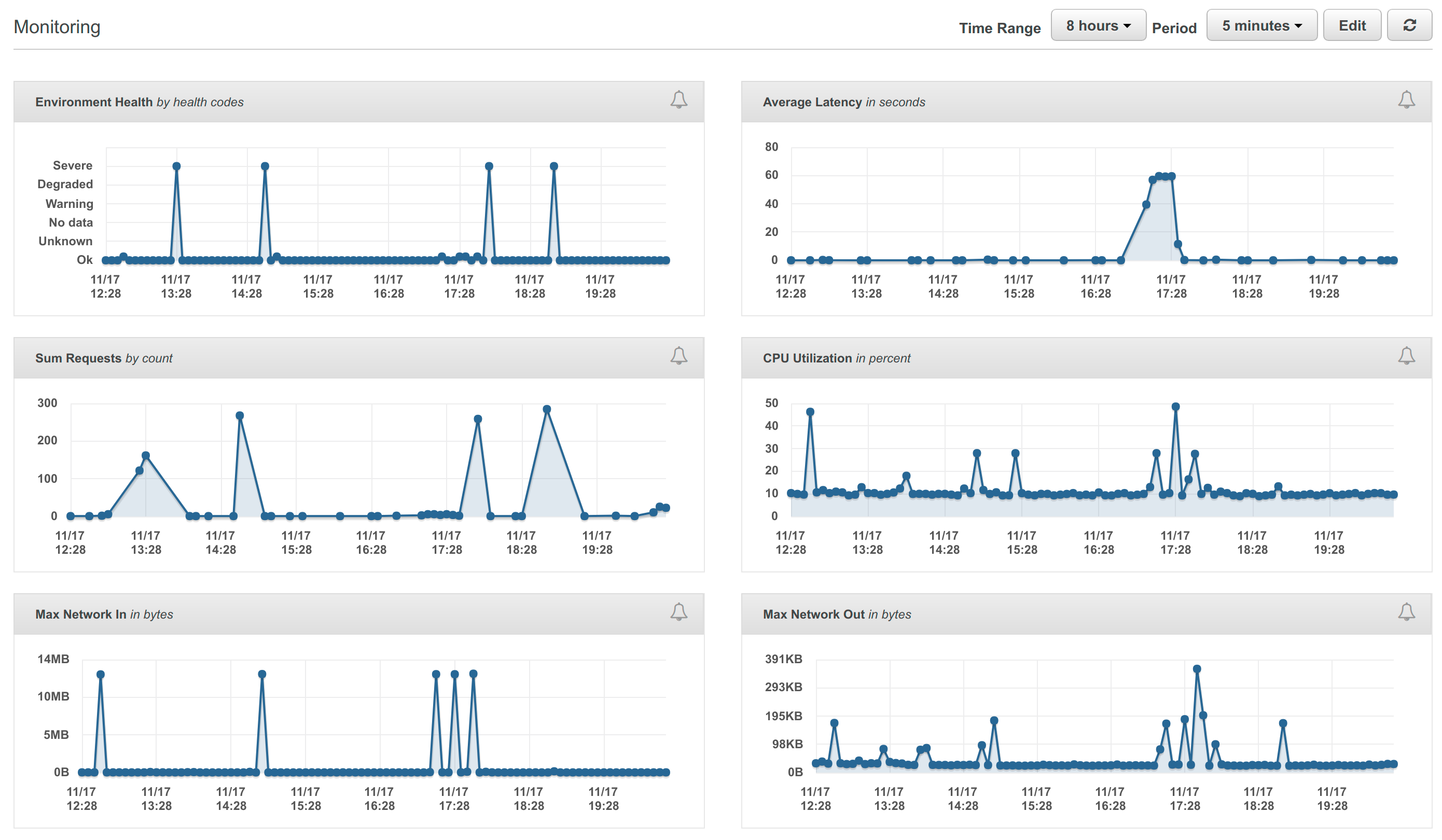
Well, I had a bit of a disaster during the week. On Thursday morning my laptop stopped charging, and now it’s in the shop being repaired for a hefty fee. It’ll be back some time during the week.
Luckily I have this other, smaller, laptop, so I can still do my work. It only took 7 hours to update it with all the work stuff… Well I guess that’s quicker than many other problems could have been resolved.
The bad news is that this laptop seems to be too underpowered to work on Extended Stats, which is not that big of a project, but it is a kinda complex one – it includes about a dozen Angular applications, and a couple of dozen Lambdas in a variety of locations, and I think the editor gets confused by the non-standard organisation.
Even worse, one of the bits of code that’s on the broken laptop is the autocomplete demo, which is one reasonably small thing that I could potentially have worked on on the smaller laptop. So that sucks as well.
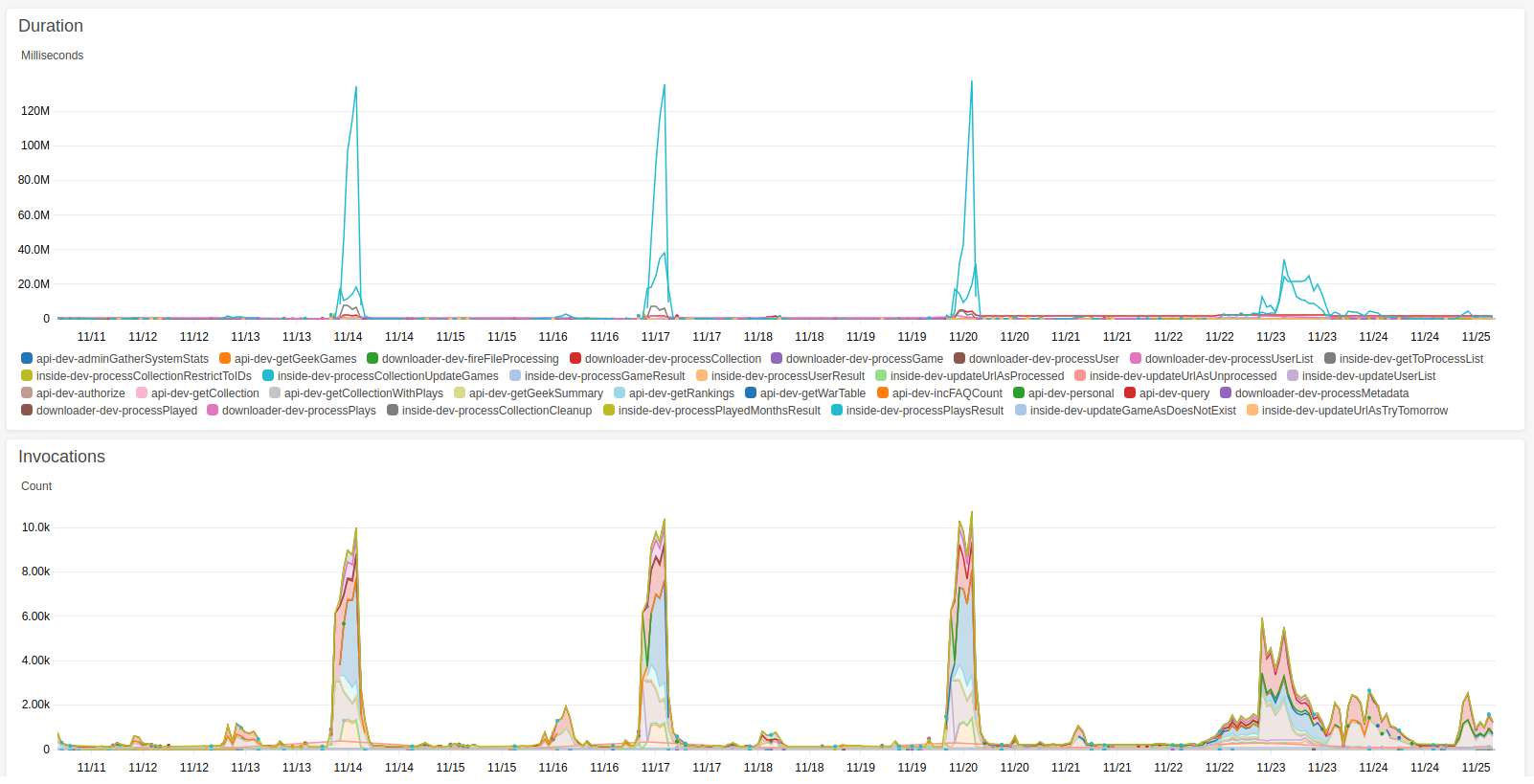
Nevertheless, there is something to talk about. The work I did last weekend on putting the code in Elastic Beanstalk was aimed at preventing the really spiky bits in the Lambda performance graph (because they cost me money). Over the last couple of days we’ve been going through a period which should be spiky, and it has definitely changed.
By the way, these bits correspond to the update of all the users’ collections and played games, which happen every three days. I did two things.
First of all, I rewrote the bit that was appearing light blue in the bottom graph, because as explained in this post:
it was costing me a lot of money.
The second thing I did was to change “every 3 days” to “about every 3 days”. So when I schedule an update, I don’t schedule it for exactly 3 days, because all that does is preserve the periodic load. And as you can see, that flattened out the load a bit, and should continue to do so. I was calling this “dithering” to myself, but now checking on Wikipedia, dithering may be something more specific than that. Nevertheless, that plan is sort of working.
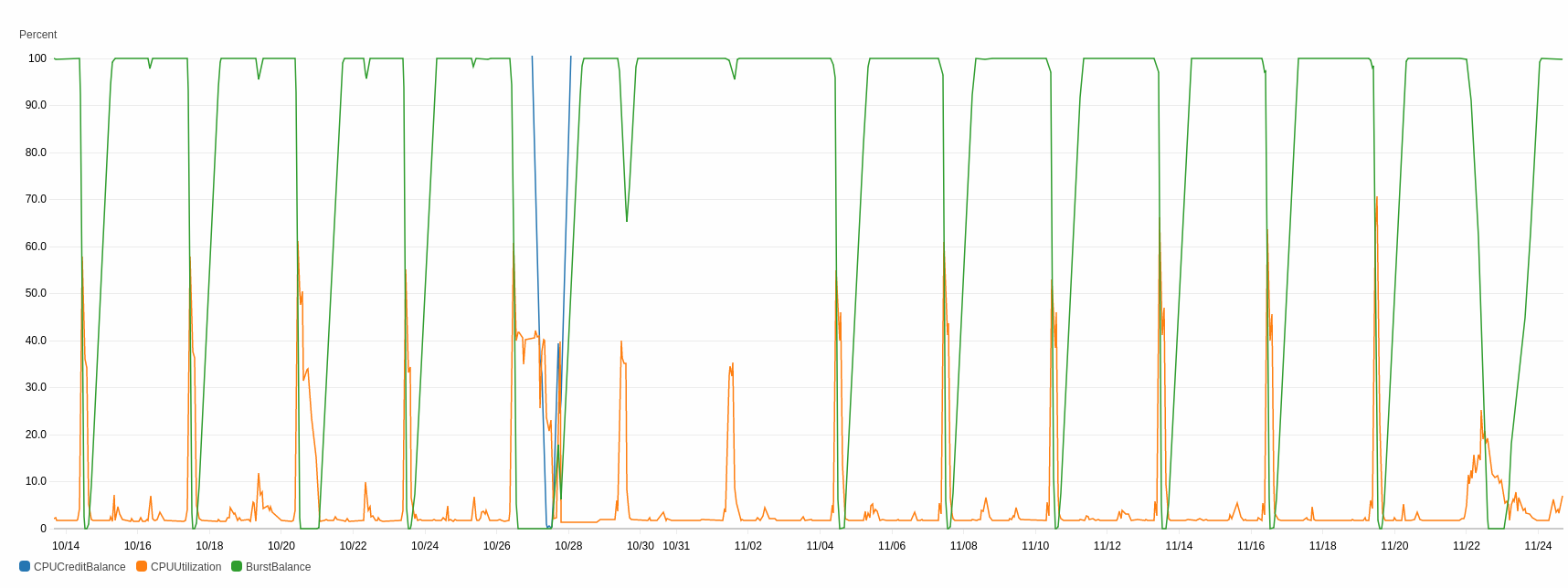
On the other hand, as Tevye would say, it didn’t seem to really help the database performance. The orange line is how hard the database is working, and making that change seemed to spread the peak out, but increase its total area. And then that caused the green line to hit the bottom for longer. And that’s bad. I’m hoping that with more dithering the green line might not get to the bottom at all.
I miss my big laptop. You don’t know what you’ve got till it’s gone.