On the weekend when I noticed that the database was worn out, I updated some code to try to make database operations for saving game data less expensive. When I turned the downloader back on, the situation was just as bad as before, which was much worse than it was last month. I didn’t really know what had changed.
I noticed in the Lambda logs that a lot of updates of game data were timing out after 30 seconds, which I thought was odd. There might be a couple of dozen SQL statements involved, which should not take that long. So I added some logging to the appropriate Lambda to see which bits might be taking a long time.
The answer was that the statement where I calculate a game’s score for the rankings table was taking maybe 8 seconds. Actually I think it takes longer if there are more things hitting the same table (the one which records geeks’ ratings of games), so 30 seconds is not unbelievable. But it is bad.
I checked out the indexes on that table, and realised that I had relatively recently removed an index on that table – the index that lets me quickly find the ratings for a game. So it seems that the lack of that index was slowing the calculation of rankings down, and hence causing updates to games to wreck the database.
So I fixed that index, but there was a reason I took it off. MySQL InnoDB (not sure what that even means) tables have a problem where if you do lots of inserts into the same table you can get deadlocks between the updates to the table and the updates to the indexes. I figured I didn’t need the index on games so much, so I took it off to fix some deadlocks I was seeing. Silly me! Now I suppose the deadlocks will come back at some point.
Next time though, I hope to remember how important that index is. I’ll just rewrite the code that was deadlocking to do smaller transactions and retry if it fails.
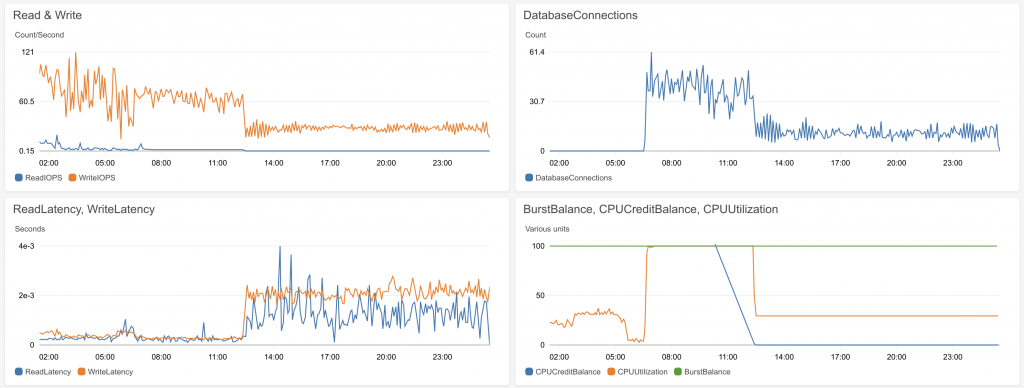
Hmm, something bad happened yesterday. Database CPU went very high, and database capacity was exceeded and it used up all of the burst capacity. That means the database is worn out for a few hours until it recovers. I wonder what went wrong? I suspect one of the Lambdas went crazy and ran too many times, but I don’t have a good idea why that would happen. For the moment I have turned off the downloader so it will stop hassling the database.
These graphs show database performance. The top-right one is probably a cause – lots of incoming connections – and the bottom right one is a consequence. In particular the blue line diving into the ground is a bad thing.
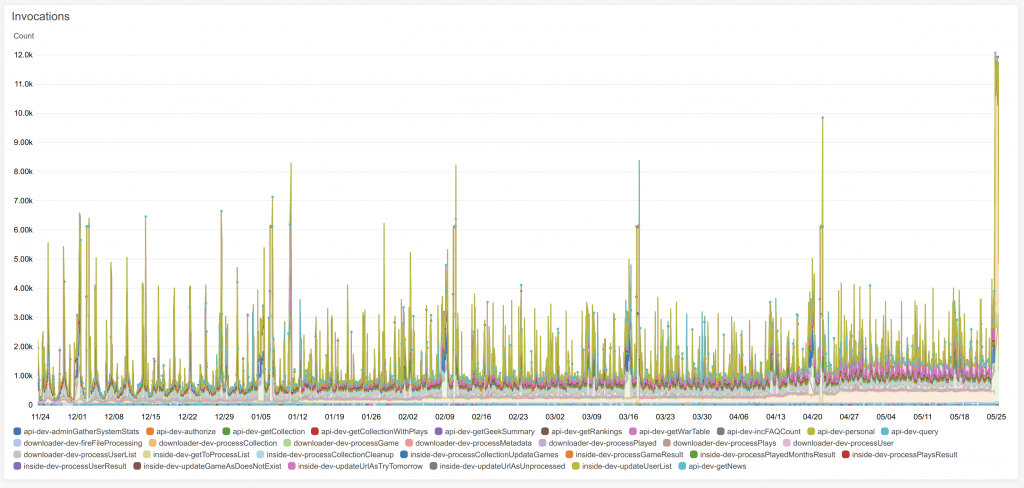
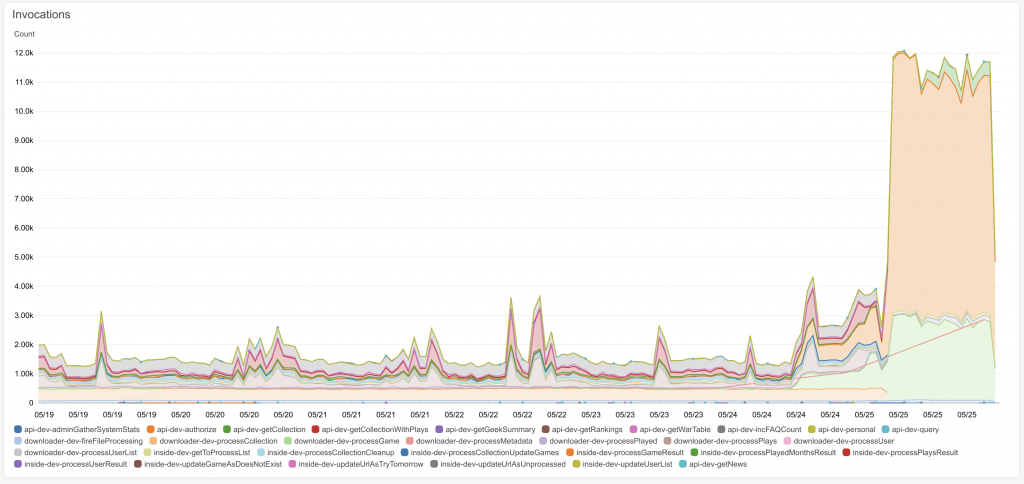
Looking at the Lambda invocations, it seems about every 35 days there’s a spike, and yesterday’s spike was the biggest ever.
Taking a closer look at the spike, we can see that it was the oranges and the greens wot dunnit. Greens are downloading data about a game from BGG, and orange is storing that game in the database.
I just checked the code, and each game is updated every 839 hours (there’s a boring reason for that). So, that would be what’s causing the problem – every 35 days, I go to update 66000 games, which causes 66000 Lambdas to download data from BGG (sorry Aldie) and then 66000 Lambdas try to update the database. It seems I need some more dithering.
Cry ‘Havoc,’ and let slip the dogs of war; That this foul deed shall smell above the earth With carrion men, groaning for burial.
It really has been trench warfare this week. My last post was about the database crash. That took a day to get better by itself, but after discussing the matter with the AWS people on reddit, I decided that this was definitive proof that the database was too small, so I dumped it and got a bigger one. Which is a shame, because I think I already paid $79 for that small one.
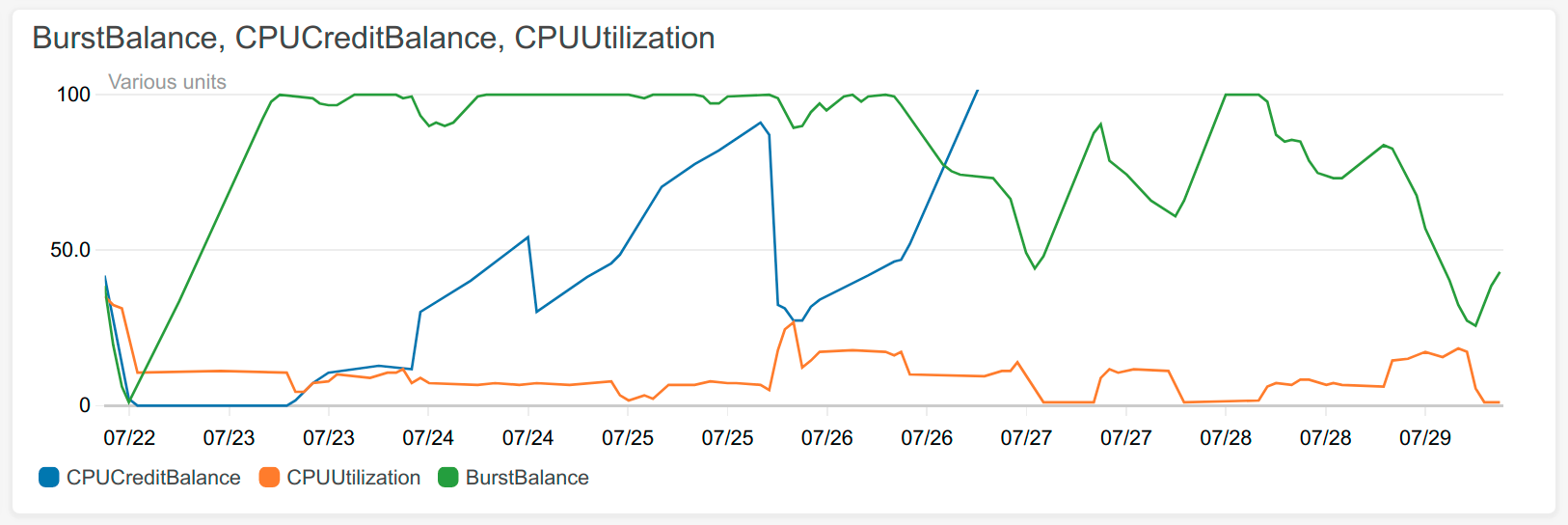
The database hovers between life and death for a week
Anyway, the bigger one is still not very big, but if I recall correctly it will cost about $20 / month. When I get some funding for the project I’ll probably upgrade again, but for the moment I’m struggling along with this one.
The graph above shows CPU used in orange. It’s good when that’s high, it means I’m doing stuff. The blue and green lines are the ones that broke the database during the crash, and they must not be allowed to touch the bottom. Particularly notice when the blue line hit the bottom it stayed there for most of the day and the site was broken. So let’s not do that.
So in response to this problem, I made some changes so that I can control the amount the downloader is doing from the AWS console. So in the graph, if the orange line goes down and the green line goes up, that’s because I turned off the downloader. And then later I turn it back on again. The initial download of games is about half done, so I expect another week or two of this!
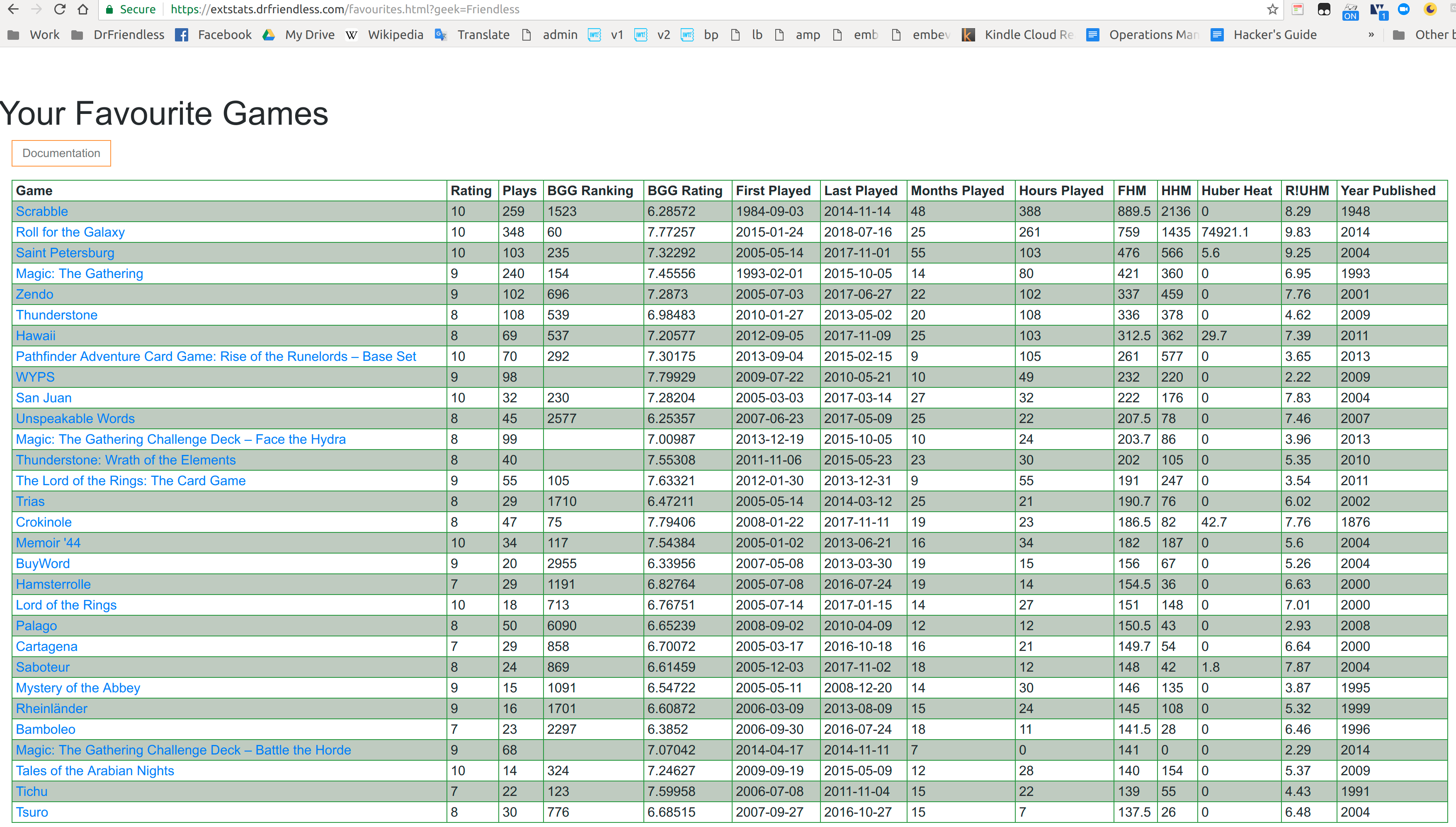
The Favourites Table
On the other hand, the good news is that there are plays in the database, so I started using them. My project yesterday was the favourites table, for which I had to write a few methods to retrieve plays data. That bit is working just fine, and the indexes I have on the plays make it very fast.
The table comes with documentation which explains what the hard columns are, and the column headers have tooltips. There are other things about the table, like the pagination, which still annoy me, but I’m still thinking about what I want there. Some sort of mega-cool table with bunches of features which is used in all the different table features on the site…
That was a major advance, so I decided today to follow up with some trench warfare, and had another shot at authentication. This is so that you can login to the site IF YOU WANT TO. I went back to trying to use Auth0, which has approximately the world’s most useless documentation. When I implement a security system I want to know:
where do the secrets go?
how can I trust them?
what do I have to do?
Auth0 insists on telling you to type some stuff in and it will all work. It doesn’t say where to type stuff in, or what working means, or what I have to do. I know security is complicated, but that doesn’t mean you shouldn’t even try to explain it, it means you have to be very clear. It’s so frustrating.
You can sign in but why would you?
But anyway, after a lot of failures I got this thing called Auth0.Lock “working”, in the sense that when you click Login it comes up, you can type in a username and password, and then its happy. I get told some stuff in the web page about who you are.
The remaining problems with this are:
when the web page tells the server “I logged in as this person”, how do I know the web page isn’t lying? Never trust stuff coming to the server from a web page.
there are pieces of information that the client can tell the server, and then the server can ask Auth0 “is this legit?”… but I am not yet getting those pieces of information.
I have to change all of the login apparatus in the web page once you’ve logged in, to say that you’re now logged in and you could log out. But that’s not really confusing, that’s just work.
One of the changes I had to make to get this going was to change extstats.drfriendless.com from http to https. That should have been a quick operation as I did the same for www.drfriendless.com, but I screwed it up and it took over an hour. Https is better for everybody, except the bit that adds the ‘s’ on is a CDN (content delivery network) which caches my pages, so it means whenever I make a change to extstats.drfriendless.com I need to invalidate the caches and then wait for them to repopulate. And that’s a pain.
Nevertheless, I’m pretty optimistic that Auth0 will start playing more nicely with me now that I’m past the first 20 hurdles. Once I get that going, I’ll be able to associate your login identity stuff like what features you want to see. And then I will really have to implement some more features that are worth seeing.
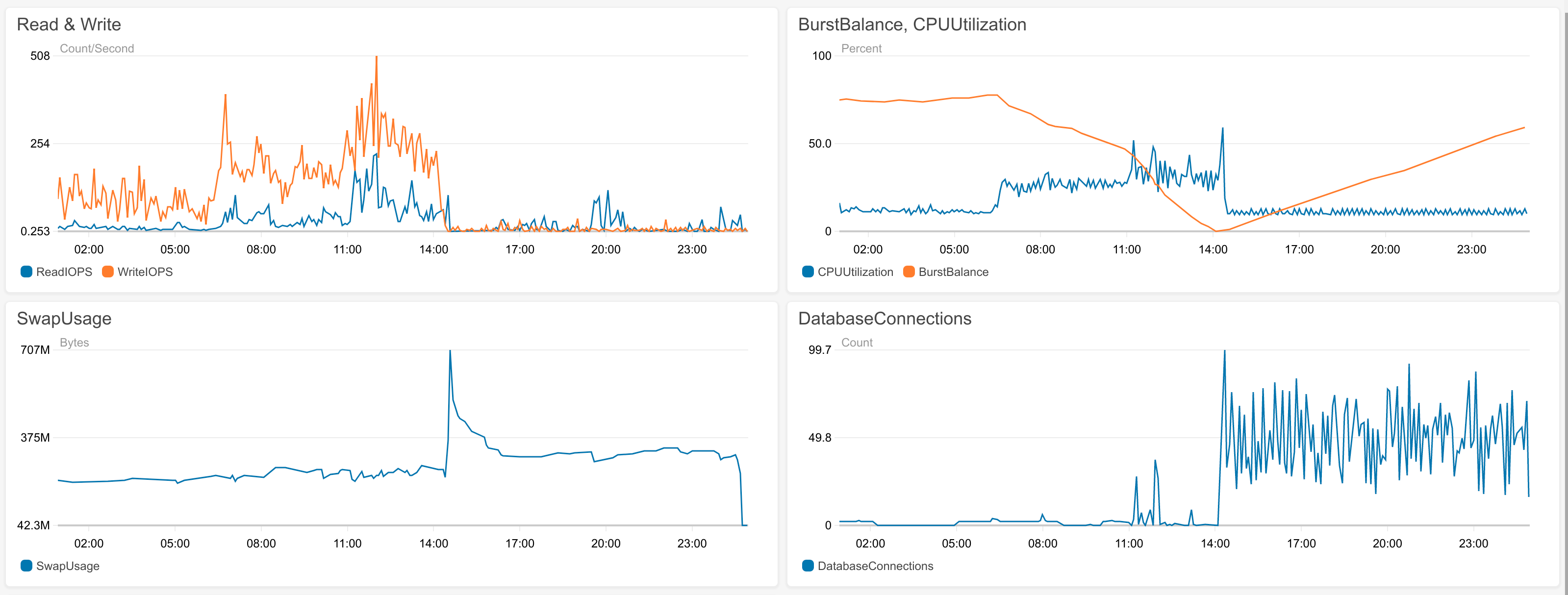
So, a couple of hours after I wrote the blog post last night saying how everything was going full steam ahead, it all blew up. This morning, many bits of the system which were working just fine are failing. This points to the database, which is at the heart of everything, and all indications are that it broke at about midnight.
I had a poke around, and eventually found the BurstBalance metric. In the top right graph, it’s the orange one that dives into the ground and bounces up.
What it seems to be is that if you overuse your database (in particular, the database’s disk) , you eat into your overuse credits, i.e. the burst balance. And at midnight I ran out of burst balance so the database stopped responding.
Well, that’s something I learned today. At least now I know to watch this when the system is under proper load. It’s also a good indication of when it’s time to fork out for a bigger database.