Oh goodness, wake me up when this post is written, please. Money bores me senseless. However as some who is seeking donations I feel it’s my duty to be transparent about what those donations are being used for. Despite the fact that when the AWS monthly bill comes in I kinda dread reading it.
Anyway, yesterday I mustered the willpower to update my spreadsheet of costs over time. It was a bit terrifying.
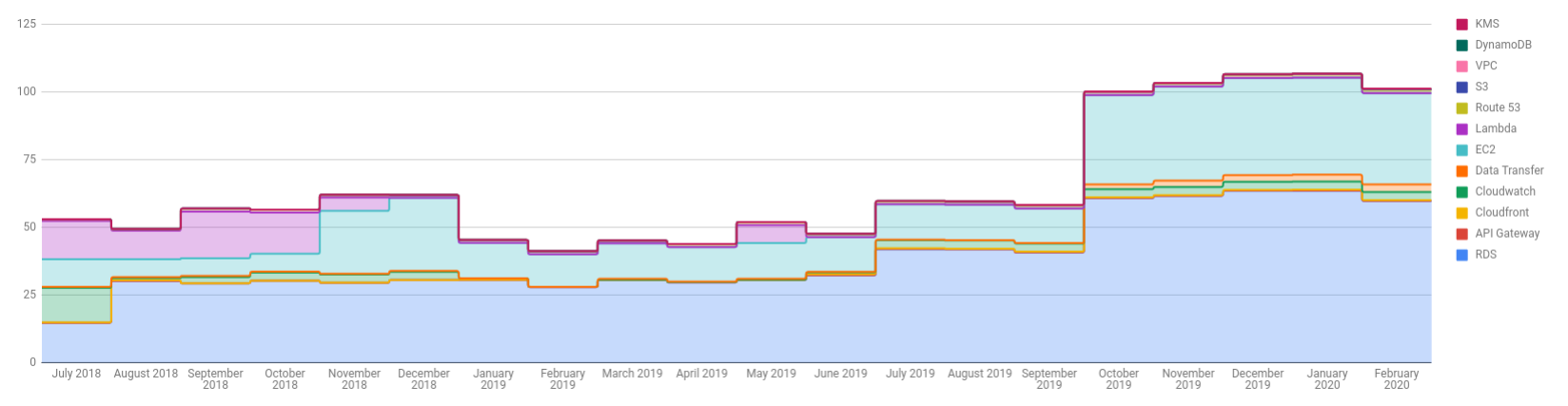
Graph of AWS Costs Over Time in $US
Costs rose very dramatically in October. That was when I had the hardware failure and did the lift and shift to get the old site running in the cloud. As that required a new EC2 (virtual server) and RDS (database), I knew there would be increased costs. Everything else is pretty stable though, but I will keep an eye on DynamoDB and data transfer, as they are increasing.
The site is now costing me in the order of $A170 per month (note that the graph above is in $US, and it’s about $US1 = $A1.5), which is almost enough motivation to do something about. Other bits of life are getting in the way though, such as a terminally old dog and so on.
On July 1, which is the start of the new tax year in Australia, I took a payout from Patreon of all the money that was there, and it was $A69.92. I declared that on my tax as I am required to do. And thanks to all of my lovely patrons for helping me! Patreonage has continued to increase slowly – it would probably help if I worked on the site a bit more – so that’s looking good.
I would like to get rid of the lifted and shifted site. I’ve had report it’s too slow anyway, and it would cost more to make it faster. However there’s an experiment I’d like to conduct on it – to migrate it to new database technology that scales better and could possibly be cheaper. It would be informative to me to see how well that goes.
Oh well, the site is not making me rich. However if I have to spend long months locked away from the world due to a COVID-19 outbreak, I’ll have plenty to do. Thank you all for your support.
So, this is Christmas. I don’t know what Christmas is like for you, but it’s quiet for me these days. My family lives interstate, my wife is not a Christian, and my idea of a good time is fixing bugs. So we spent Christmas at home and did very little.
However I did get a bit of a chance to work on the site. I managed to:
remove deleted BGG users
discover that one of the Lambdas I’ve been invoking apparently never existed (whut? maybe I got distracted before I finished it?)
write a new email response for new users
send email responses to 20 or 30 users
added a “number of plays column” to the updates page, so you can compare the count to BGG easily
fix the SSL certificate on the old server
install a new kernel on the old server
write a blog post so you know I’m not dead!
Tomorrow is also a holiday, although we will be having people over. Maybe I will be able to ignore them and finish the new feature that I’ve had on my smaller laptop for about the last 3 months. I wish that every day could be Christmas Day, where people do their own things and don’t hassle me… happy holidays, team!
I just received an email from an annoyed user of the site, that they had not been able to access the old site for ages. I thought that was a bit harsh as I am now running 3 versions of the site, but then I realised that it was my fault, as after repairing the physical machine that the old site runs on, I had forgotten to re-enable the hostname to point to it. So it turns out that I’m forgetting how it’s all configured, and it’s entirely reasonable that other people will be confused as well. So let’s go through it all from the beginning.
There’s the PC in my study. It’s running stats.drfriendless.com (since I fixed it a minute ago). I suspect it is doing quite a poor job of it, but since I have to get past a bunch of people to get to it to find out, I won’t know for sure – my wife and my niece work in that room. The HTTPS on that system is a pain, and I have to go in there to fix it again soon.
There’s a virtual machine which duplicates that PC, and it’s called stats3.drfriendless.com. It’s more reliable than stats.drfriendless.com as it is not subject to physical problems and does not run over my home WiFi. So I think in the future the VM will become stats.drfriendless.com – probably in summer, when the PC overheats, that will become a necessity. The downside is that it’s a bit expensive to run that system – maybe $50 / month – but I consider that a tax I have to pay because I have not got the new site doing as much as the old site yet. (Hmm… and I just discovered that some pages that load on stats.drfriendless.com don’t work on stats3.drfriendless.com. *sigh*)
And then there’s the (mostly) serverless system, extstats.drfriendless.com. I can’t see that breaking due to anything except funding problems. Serverless architecture is just so robust – if that site goes down, probably half the internet is down with it. However that site still needs a lot of work to be done.
The other thing to consider is the state of me. I haven’t been doing so much work on the site for a couple of months, and it’s hard to say why. I am spending a lot of time taking my dog to the vet – this is the same dog as I’ve had since the site started, so she is very old now. So even if I wake up energetic and enthusiastic on a Saturday morning to get some work done on the site, at about 9am I have to go for a very very slow walk to the park and back, and usually then drive her to the vet for an arthritis injection. It breaks my concentration, occupies my time, and makes me sad. She has been such a wonderful dog for such a long time, and now she’s almost an invalid that we have to take care of. So when she finally shuffles off this mortal coil, my life will change, and I hope I will take more time to do my own things.
And then there’s work. Goodness me, I am a devoted and conscientious and competent worker! But that means that my head is full of work stuff, and not so full of stats stuff, and it’s a bit hard to motivate myself to think about a whole different set of problems just because the name of the day changed. But the problems also interbreed – it’s quite common that my boss will forward me some email from AWS telling us to deal with some problem, and I have got the same one at home. So I experiment at home to make sure I know how to solve it!
When I’m feeling slack I always console myself with the thought that the old site was built over about a 5 year period, and we went through years of problems while I sorted out hosting. We got through that, and I’m sure the new site will get through its current problems as well.
I’m so far behind that I have to blog about what happened last weekend. My wife was away so I had a bit of time to myself which I planned to use doing some work on the site, instead of acting like a human being and having a life.
The first plan was to fix the Login button on the front page. What happens is that I display both a Login and a Logout button, then I make a call to the server to find out whether you are logged in or not, and then I remove the irrelevant button. That was working, but it was very slow due to Lambda startup time, so the two buttons both displayed for a disturbingly long time. So I wanted to move the API for whether you’re logged in or not into the “Elastic Beanstalk” server. I put that in quotes because although I still call it that, Elastic Beanstalk is not involved at all. Elastic Beanstalk is a service which would start another one of those servers if the first got overwhelmed. I had that working until I discovered that Elastic Beanstalk costs extra money, and as it was unnecessary I took it out.
Anyway, I moved that service as planned, and it didn’t work. It turns out that API Gateway – the bit where I say which server or Lambda each URL goes to – has very firm poorly documented opinions about HTTP headers transiting through itself. And since the cookie which says whether you are logged in goes in a header, it didn’t want to send it. In fact I still don’t have that working. And as much as I understand how HTTP and CORS and API Gateway work, I’m not sure how it is ever going to work, although it seems very much like the sort of thing that should. So after many many hours, that problem got put on the backburner.
The check for whether you’re logged in or not is a bit quicker, but it always says you’re not logged in, because the cookie is never sent to the server. I’ll figure it out.
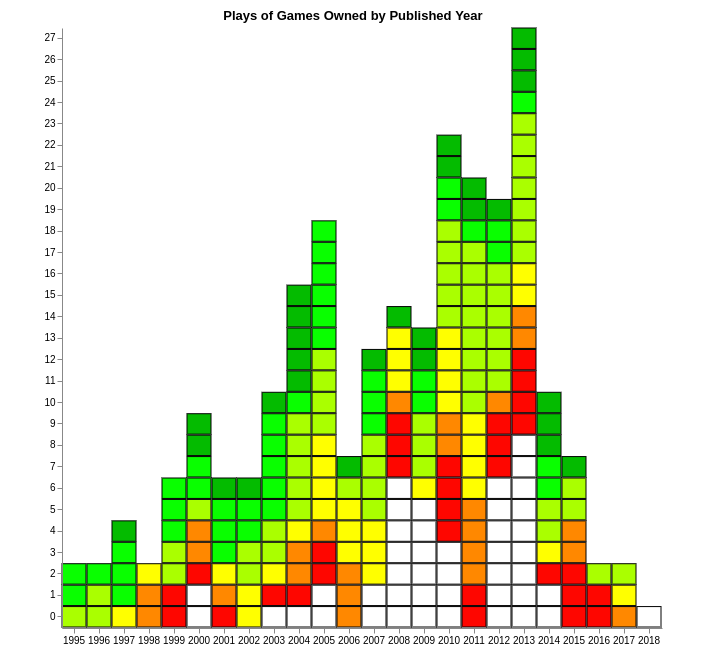
The other thing I worked on last weekend was also supposed to be easy. It was the Plays of Games Owned by Published Year graph, which looks like this:
This graph goes on the Owned page, which I hadn’t touched in a while, so I started by updating the libraries I use to make it. Well, that was a mistake. For four hours I juggled library versions, checked commit logs, and researched why the heck I was getting the wrong version of TypeScript. OK, the wrong version of TypeScript was totally my fault, but the rest of it was not and it was annoying.
But then I got the page running again, and I could add the new graph. That just involved confusion about how Vega allocates colours to data points, and a few things being upside down and the wrong size and so on, as happens in this sort of work. And then it was finished and I sent it out to the site and dragged my sorry backside to bed. It really does get a bit wearing, doing things that don’t work, all the time.
But of course this morning I was optimistic and naive again, and at 7am I started adding another feature to the Owned page. This time I didn’t need to upgrade any of the libraries, but I did discover that some of the data I wanted to display, in particular whether you had a game for trade, was not available in the data set I was using, so I had to fix that. And then I decided that rather than improving the REST data set, I should use the GraphQL data set and improve that. So I ended up creating a new version of extstats-core, a new version of extstats-angular, a new release of the API, and converted the whole page over to GraphQL. And then, only 6 hours after I started (some of which were spent on domestic duties), I got the “Why Do You Even Own This?” table working on the new site.
On the whole though, today’s mucking around was much more productive than last weekend’s. GraphQL is kinda lovely, and much easier to work with than REST, and the changes I made today should be useful for all of the other pages as well. I think about 4 of them out of 9 or 10 use GraphQL so far. However I think if I do some more work this weekend I’ll probably just try to get some features out, rather than mucking with stuff.
As mentioned in the previous post, the old Extended Stats server blew a foofoo valve and needs parts. The fan I ordered on EBay arrived and when I went to install it I discovered that I’d ordered the wrong size. This is one reason I hate hardware. Although I love the details of software, the details of hardware bore me senseless. Why can’t they just make it out of Lego so I can hack something together rather than having to figure out exactly what thing I want?
Anyway, I ordered another fan and it didn’t arrive yet. In the mean time the idea of doing a lift and shift continued to grow in my mind. A “lift and shift” in cloud computing is when you take an existing service and dump it in the cloud without adapting it to cloud architecture at all. It’s kind of the worst, most expensive, way to get into the cloud, but it’s also the quickest.
Another of the things I use the site for (other than being there for you guys) is experimenting with stuff. There’s a type of database that I’d like to try at work, which would be a huge risk for the company, but I can muck with Extended Stats for a few hours without anyone losing too much money. I mentioned the idea of experimenting on the stats site to my boss, and I suspect I might be able to get him to throw me some funding… so yeah, that’s gonna happen.
So as you might guess I did the lift and shift. It took a few hours, spread over two weekends, as as usual everything in Django seems to have changed between releases. And then I had an annoying problem where the web server couldn’t find the code, even though everything was configured perfectly, and that took me a good 3 hours to figure out – my home directory had permissions which prevented the web server from seeing the code! Late last night I got that sorted, and the new site started to work.
Then this morning I spent another hour or so getting the downloader to work. And then, in a small brain explosion, I told git (the version control system) to undo all of my changes… so then I had to go and fix all the things again, which was not at all what I had planned.
But now it seems that http://stats3.drfriendless.com is working OK. You might notice that there’s an S missing from HTTP. That’s another problem for me to sort out! I’ve come to realise that I don’t particularly enjoy solving AWS configuration problems, so I’m not really looking forward to that one. I could do it with a load balancer (which is expensive) or with a CloudFront CDN (which is annoying to configure but I suspect I’m getting OK at it by now). Or I could try to do SSL termination in Apache – actually, nah, that’s the sort of thing that will just make more work for me later.
Well, that’s how I spend my weekends! I’ve been hearing cries from the crowd asking for utilisation numbers on the new site, and I have no idea why I haven’t done them yet. So I might try to do some programming and get those happening. I like programming, it’s better than configuring web sites.
So this is not a good news post (the sort that says “I added features”) but this is not a bad news post (the sort that says “I’m giving up computing and going to live on a remote island with Aishwarya Rai”), it’s a just a post to tell you that despite all the evidence, I’m not dead and Extended Stats is still on my mind.
I’ve been trying to solve a problem connecting two bits of AWS together. Two years ago I would not have understood the problem, so I will not try to explain it to you. In fact two years ago I had a similar problem that depressed me so much that I stopped working on Extended Stats Serverless for about 4 months – that was before I announced anything, and I was doing a proof of concept, and I could not prove the concept. So I knew that it might be difficult, but really if I want to do AWS development I have to be able to work through these things.
Anyway, the good news is that with a lot of research (i.e. even checked sites other than StackOverflow, and I read documentation), and a lot of daydreaming, I have fixed this particular problem.
Daydreaming is an important technique in computer programming. When something doesn’t work, and it damn well should, my approach is to do something else and dream about what stupid thing might be happening. So I dream about how one bit probably works, and what its concerns are, and how the other bit probably works, and what its concerns are, and what might be missing in the middle. I find it’s best to do this in the shower, so all development offices should have showers :-). However today I figured the problem out while cooking breakfast. I wanted to watch Peaky Blinders, but once I thought of what might be going on I had to turn off the TV and try it out!
Anyway, that’s good news. I am very conscious that the old site is still down (I need a case fan. There is one computer store I know of that I can drive to, so after dropping my wife at work on Wednesday I went there, and they didn’t open till 10am. It was 9:30am and I’d already spent enough time not doing what my boss was paying me to do. I gave up and ordered a fan on-line.) and I need to address that. The new site is all people have at the moment, and it still doesn’t have the content people want.
This is why I need to move the site into the cloud! The fan in my server has gone out of balance or whatever they do, and started making a weird grinding noise. My wife and my niece, who both work in that study, complained about the noise. I had to shut the machine down, because if the fan dies in the middle of the night and the machine overheats, everything is dead, which would be bad.
Come to think of it, that study is not air-conditioned, and I’m expecting summer to be hotter than ever. I’m not sure the machine will be healthy. I might have to consider doing a lift and shift, and putting the old site into the cloud as well. As long as I use a local database (on the virtual machine, not managed by AWS) it will only be a little expensive. Hmm… I’ll go have a shower and think about that…
I have been a bit slack with this project recently, but I’m going to blame most of that on playing games. I’m dungeon master in a D&D campaign, and I spend a lot of time researching things like “what’s the most explosive substance there is?” and “what are the middle names of the member of Destiny’s Child?”, even when I’m not at the gaming table being way too extroverted.
However I have indeed also been working on something for the stats site. One of my intentions is that the data presented on the site be customisable – if you don’t want to count expansions, then you shouldn’t have to. To this end, all of the data presentation pages take a selector which tells them which data to present. In case you have never heard of selectors before, they’re a formula which specify which set of games you’re talking about. The selector for the Favourites page is “all(played(ME), rated(ME))“, which means “games which have been played by me and rated by me”. Now you might very reasonably want to further restrict to games that you own, or to exclude books, or to only look at children’s games. So ideally you would be able to edit the selector.
On the Favourites page you used to be able to, but it looks like I recently broke it, and the interface to do it was pretty hard to use. So I am working on making a new one. That comes in two parts.
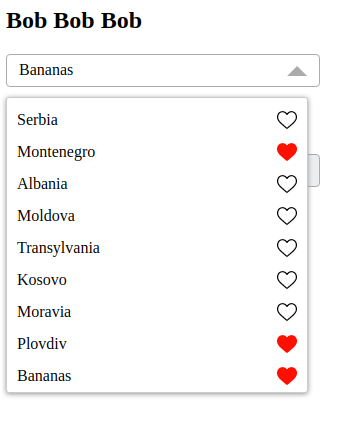
The page itself will have a basic selector which makes the page work. The Favourites page can be run against games you haven’t played, but it makes for some pretty bad data. In fact the page can suggest a variety of different selectors that I think are useful. These are presented in a dropdown list box. Furthermore, you can type into the list box, either to find an existing entry or to add your own entry. And of the entries in the list box, you will be able to mark some as your favourites.
No such UI component like that exists, so I wrote one. I just got all (well, most) of the finicky details working this morning, and put the code on GitHub here: https://github.com/DrFriendless/favcombo . It looks like this:
Yes, one of my favourite Balkans regions is Bananas. We all have our quirks.
When you come to the page, the options in the list box will be the suggestions from the page plus any that you previously marked as a favourite. So if you added a selector that you liked, it will be stored for you. Note to self: this will only work if you are logged in, in fact it’s cruel to let you favourite things if you’re not logged in.
But to make that work, I need to do some work on the storage and retrieval of personal data for logged-in users. I haven’t got to that problem yet, I guess it’s what I’m looking at for the rest of this weekend!
There’s also the issue that the site logs you out too soon – it annoys me so much that I don’t generally bother to log in, and it’s my site!
Anyway, as you see things are happening bit by bit. I’m not dead yet. You can’t kill the DM.
I can imagine the despair out there in gamer land, when you realise that this is another post about technology and not about the site actually doing something. Yeah… sorry about that. My nerdiness is definitely trending towards tech at the moment.
Anyway, Terraform is nothing about Mars. It’s software for specifying what to do with Amazon Web Services. For example, for Extended Stats, it might include stuff like this:
there’s a database
there’s a Lambda which runs every 10 minutes, which looks at a file on pastebin to see who the users are
there’s a Lambda which looks at BGG to get data about users
there’s a host called extstats.drfriendless.com
there’s an API Gateway which connects the host extstats.drfriendless.com to some Lambdas.
and so on… there would be a lot of it.
At the moment I use a technology called Serverless to do that sort of thing, but I am not very good at it. On the other hand, after a couple of days of Terraform, I’m really getting into it. It seems better designed and easy to use.
Sadly I suspect it would be a lot of work to change from Serverless to Terraform for Extended Stats, though I will have to one day. Extended Stats is a poor combination of Serverless and ad-hoc undocumented changes made in AWS. This is fine for Extended Stats as it is, but it would be difficult for someone to reproduce the site.
In particular, the tricky bit is specifying the security permissions, which allow different bits of the project to use / modify / read other bits. For this Terraform stuff I’m doing, I’m very carefully doing even that in Terraform. For Serverless, I have not been so careful (because it was too annoyingly difficult!).
Anyway, it’s cool. One day I will get to use it in anger. Tomorrow though, I suspect I will have to write some features for you.
So there’s this technology called GraphQL (graph query language). It’s a way of getting exactly the data you need from a database using HTTP. That’s a vast oversimplification, but I am not writing an academic paper here.
When I started the site I couldn’t imagine a need for it, as for the pages I know exactly what data I need, so I figured I’d just write API methods that retrieved that data. (That’s what’s happening when you see those 8 pulsing blobs.)
But then I wrote the Comparative Plays page, and that thing requires a boatload of data. At first, it required all of the plays of all of the geeks, and all of the data about all of the games that they’d played. And then I tried to open the page with geeks Friendless, jmdsplotter, and Nap16, and AWS Lambda said “BZZZT! That’s more data than I can return!” That was when I realised I would need to think harder.
So I did an experiment where I fetched the data for Friendless, ferrao and Simonocles. That was 1,462,103 bytes, which is a LOT of data for just one graph. So I mucked around and rewrote the code to only send the first play of each game, and that was 632,447 bytes. And then rather than send year, month and date for a play separately, I just sent YMD, e.g. 20190712. That got it down to 587,717 bytes. And then I realised that I was doing a lot of futzing and there was still a lot of data I didn’t really need still coming, for example the minimum player count for games, and so on. So I decided to think about it very hard for a while.
I then slowly realised that selecting the values you want was one of the things GraphQL offered. So I did some more reading and I did not get how it was supposed to work, but I did find a very nice tutorial written by a bearded gentleman about how to use GraphQL on AWS Lambda. So I sat down one evening earlier this week and copied that code into my API, and after an hour or so got the basic example working. And that was when it clicked what it was doing, so I then proceeded to implement a query for plays following the same pattern. I got it working that evening, in a shambolic kind of fashion. The next evening I came back and cleaned it up and was able to rerun the query for Friendless, ferrao and Simonocles, and it came back with 214,470 bytes. Woohoo! And in transit, that gets gzipped! So I was pretty content with that (because remember, I pay for bytes which come out of the server).
And then the next day I updated the Comparative Plays page to use GraphQL, which wasn’t as easy as it sounded – AWS blatantly lied about the error it was giving me – but in the end it was all good.
Well, there was one moment of neurotic anguish. It turns out that for a game, in that graph, all I need is its number and name. (In fact all I need is the name, OMG OMG OMG, no I will worry about that later.) However I have a nice set of definitions of what a Play is, what a Game is, what a GeekGame is (it’s the relationship between a geek and a game, e.g. the rating), and now with GraphQL I’m saying I’m going to call it a game, but it’s really just a number and a name. And TypeScript is not overly pleased with that, and pedantic programmers aren’t either. So I will have to think about my neuroses.
But now I’m like a man with a hammer! So many things I’ve done in the API can be done better in some other way. Everything should be rewritten! But believe it or not, even I know that’s a bad idea. So I have to restrain myself. Nevertheless there is still that thrill of having discovered a wonderful thing that will keep me interested for a while yet.
I’ve been working on login again recently. As I say every time, login is hard to work on because it doesn’t work on the test system and it doesn’t work on the development system, due to the authentication service saying “no, you can only login to extstats.drfriendless.com from extstats.drfriendless.com” which is eminently sensible but a bit frustrating. So I have to make the change, send it live, wait up to 24 hours for the CDN to put it on the site, and then I can test my code.
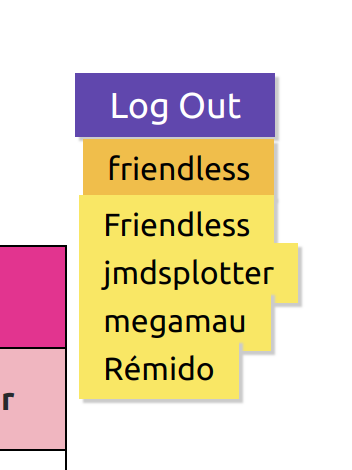
Now when I log in, I get this (we are looking at the three buttons on the right):
The presentation still needs some work – that does not come naturally to me! The orange button is a link to the user page, and the yellow button is a link to the geek page for Friendless.
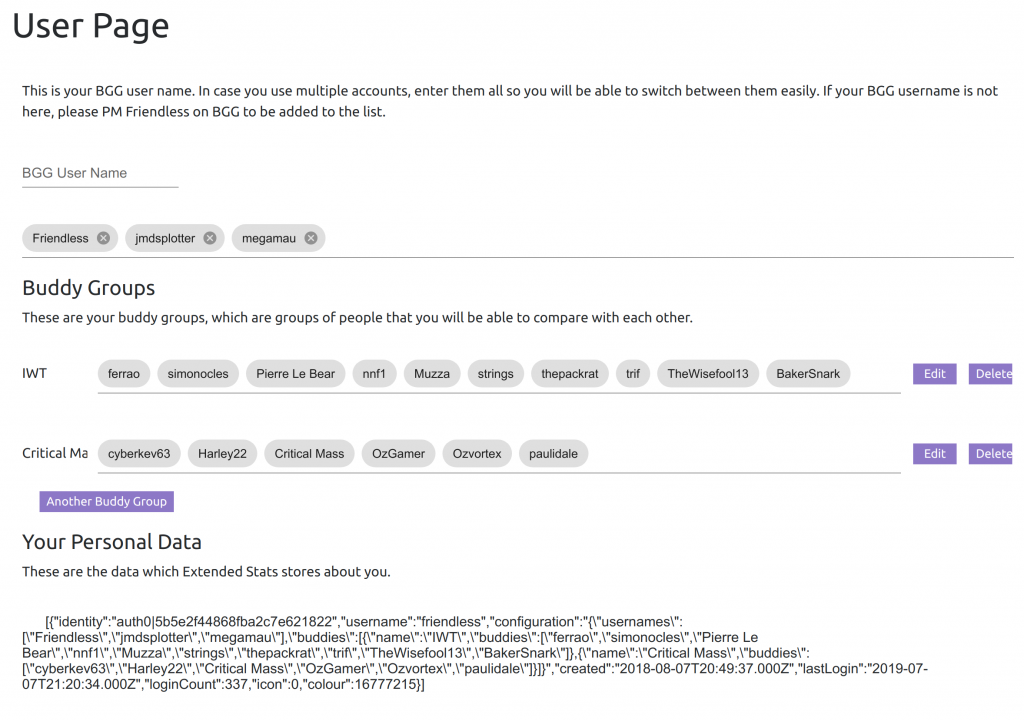
The user page is only available to you if you’re logged in. It looks like this:
The Buddy Groups aren’t used yet, not quite. What is a bit useful is the list of BGG user names above them. In that area, I can enter the list of BGG users that I am, or just ones that I like to stalk. And then when I’m logged in, those names turn into yellow links. And those will take you directly to the geek page for those users.
I’m not yet happy with the layout of the buttons, but as with all things on the site I’ll figure it out eventually.
Now that I’ve had this first success with user data, I hope to plumb it in in more places in the site, so that logging in becomes a useful thing to do.