One question I often ask myself is “why would you rewrite working software? Have you not read the millions of articles saying it’s a bad idea?”
Well, yeah… but. I started writing Extended Stats in 2004 or so, when Python was a new programming language, and I was very excited about using this new language. The plan was to just do a bit of scripting with this easy language, and see some cool numbers. At first I was generating HTML pages, and then I moved on to generating them overnight and bulk uploading to some free hosting site, and then in maybe 2008 I recoded most of the system to run in a web server and make pages up on the fly, much as it is today. And then I stopped mucking with the infrastructure, and jammed a whole bunch of features on and off until 2015.
Then in 2015 I moved states and jobs, and learned a whole bunch of new things that I would very much like to muck with. Also – and don’t laugh, this is true – the study in our new house is too hot in summer and too cold in winter, and I hate sitting at my PC. I ended up getting a laptop which I proceeded to use more than my PC. Extended Stats runs on the PC and so is kinda bound to it, so it didn’t get any love.
When I did drag myself into the study to look at Extended Stats, I found that I was struggling to decode the Python that I’d written 10 years previously. Python doesn’t have types, and types are a strong indication of the structure of a piece of code. So I’d be in the guts of the play calculation stuff, trying to figure out how it worked, without many clues from the code. And that’s bad. I know many companies are using Python for big projects, but I think that’s a bad plan. I am a doctor in this stuff, and I’ve been writing Python for maybe 18 years, so I think my opinion is not without foundation.
So, with me not wanting to go to my PC, and not wanting to look at the code, and being excited about other technologies, Extended Stats got no love. However I was still interested in the data set, and wrote a couple of applications in Kotlin to do some cool stuff with it.
And then I got a job working with Amazon Web Services. AWS is a cloud computing platform. The cloud is a great place to host software. It is a much much better place than the PC in my hot and cold study. You can get to the cloud from your laptop! I had experimented with cloud-hosting Extended Stats before – I got one version running on an EC2 (just a virtual computer), and one version running on an EC2 with an external database on RDS. However as I had no money at the time to pay hosting fees, and I didn’t really see why hosting like that would be significantly better than hosting on my PC, I didn’t bother with that plan. However, that little bit of experience with AWS came in invaluable when I ended up getting a job working with software that is hosted like that.
And then Amazon invented this thing called Lambda. Back in the 1930s, the mathematician Alonzo Church invented a thing called lambda calculus which is a mathematical model based on functions. Lambda (λ) is the symbol used to denote the start of a function. What AWS invented is a way to put your code in the cloud and let it be run without worrying about EC2s or any other sort of virtual machine. Basically you write the code, and they run it, and stuff happens. At first I was sceptical that it would be viable, but it seems that it is as they’re making a big business out of it. Furthermore it is very cheap.
That has led to this thing called serverless computing, where rather than write a program in any traditional sense, or even a bunch of services hosted inside a web server or other container, you just write Lambdas. And then you tie them together with string and chewing gum, and hey presto, you have an application that runs in the cloud. If you need to run one Lambda a month, that’s fine. If you need to run a thousand simultaneously, that’s fine too.
That brings me to another problem with Extended Stats. I’m approaching the 3000 user mark, and the bandwidth required is making an impression on our home quota. As we’re watching more TV across the internet now, and downloading PlayStation games, there could be problems. And I’d love to take Extended Stats up to 10000 or 100000 users. And that would be a problem.
So implementing the system with AWS Lambda has these advantages:
- infinite scalability
- does not use my home bandwidth
- can be accessed from my laptop, even if I’m on holidays
- does not require me to go to the study
- fun to play with
- different lambdas can be written in different languages so I can muck with new things.
That solves most of the problems I was having, except for the disadvantage:
- all the code has to be different.
But hey, I’m a programmer! I can fix that bit! In fact I love doing that bit.
I came up with this plan about halfway through 2017, and started mucking around a bit towards the end of the year. However there’s not really a standard way to do that sort of architecture yet, so I had to do some experiments which were often abysmal failures. That got a bit depressing so my interest sort of drifted in and out. Then in June this year I decided to have another bash at some of the boring bits, and got it to work. And then I got some more bits to work, and next thing you know the whole plan was coming together. So then I started a blog to keep people up-to-date on where the project was at.
Now, I admit, I could have kept some of the Python. There is a variant of Python that uses types. But even Python is broken these days. After version 2.7 of Python (I think I started on 1.5.2 or something), they went to version 3 which was radically different. So even if I did keep the Python there was a lot of rewriting to do. So… nope.
As it turns out I’m doing most of the coding in Node.js in TypeScript, which I didn’t know much about and am still not very impressed with, even though it’s doing the job.
I did decide to keep the SQL schema. They have NoSQL databases these days, but a lot of the Extended Stats data really is relational, and there’s not so much value in changing to NoSQL despite it being flavour of the month. Although the guys at the Sydney MongoDB meetup are really nice guys and I enjoy going to see them. And then, when I say “I decided to keep the SQL schema”, what I really mean is “I started with the old SQL schema, didn’t like a lot of things and changed them pretty drastically.” Creators gonna create, you know.
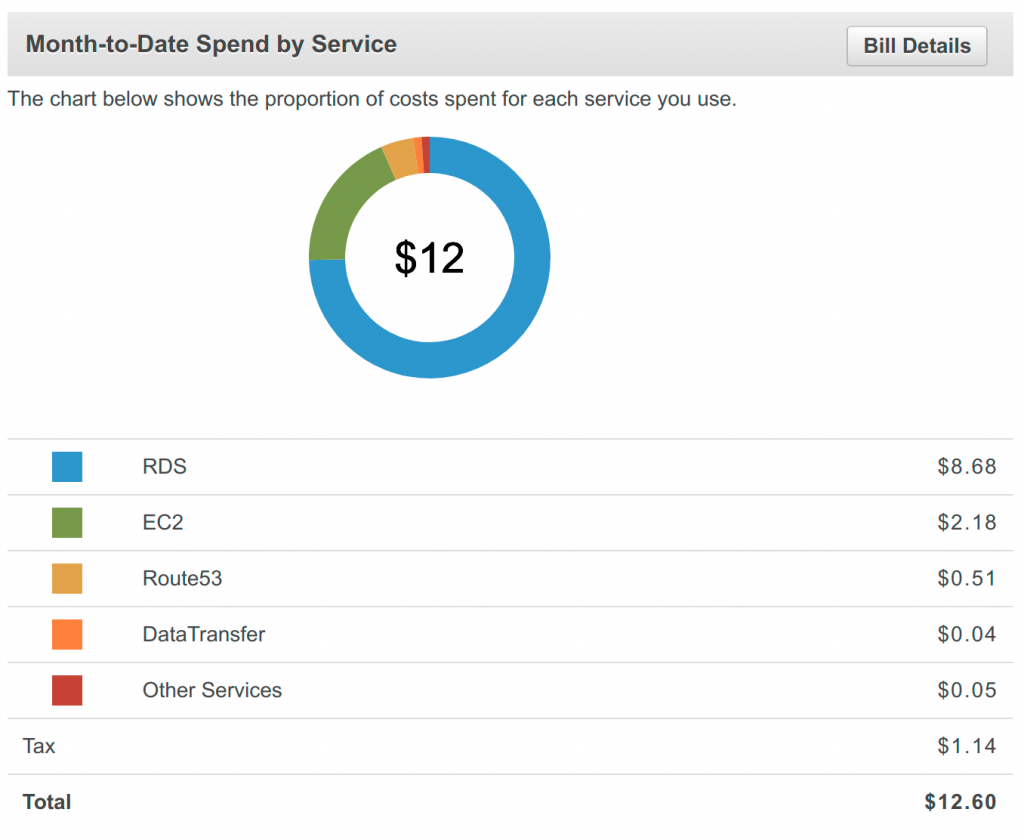
I really like where the new system is going. As mentioned in an earlier post, I got my monthly bill and it’s cheap, I’m fixing a lot of the bad architectural choices the first system evolved into, and I’m learning oh-so-much stuff and have oh-so-many great ideas. I hope you all can enjoy this as much as I do.