In case you are thinking that I am neglecting the Extended Stats project, well you are probably right. When I started the project in 2006 or whatever, my aims were to do the stats thing, but also to play with some technologies. At the time the technology was Python, then it became web-hosting, then it became cloud tech. The technologies were things I was interested in that I wasn’t using otherwise, but would like to.
These days I have a job using those technologies – this job requires most of the skills I learnt at my old job way back in 2006, plus all of the stuff I learnt building the various Extended Stats websites. On any given day I could be writing Java, Scala or TypeScript, writing Angular, improving user experience, optimising database queries, writing documentation (I LIKE writing documentation), writing financial reports (I do NOT LIKE writing reports) or building cloud infrastructure.
In June I rebuilt all of our (i.e. work’s) cloud infrastructure to be inside a virtual private cloud. I knew nothing about how to do this, but over several months I figured out all the things, and then one evening I turned off the old servers, cloned the database into the VPC, and then started up new servers. This required a migration from Java 7 to Java 8, from Ubuntu to Amazon Linux 2, from a self-hosted ElasticSearch to a cloud-hosted one, and many many other small things that I had worked on for the previous two years. There was some small collateral damage but given that I literally just replaced everything, it was mild and the project was an astonishing success.
This had to be done in June because in July we had our busiest month of work ever, with respect to server load. Customers were hammering us, and the site would occasionally break due to some limitation being reached in some new way. And when our site breaks, there are literally crowds of people waiting for it get better. So I was a bit stressed. I couldn’t get a day off, and as the site was busy on weekends I was occasionally fixing stuff then as well.
Meanwhile, Extended Stats was quietly breaking in its own way.
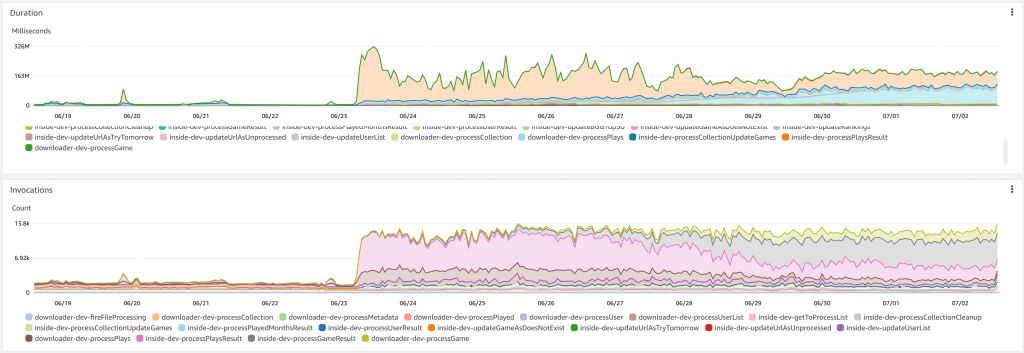
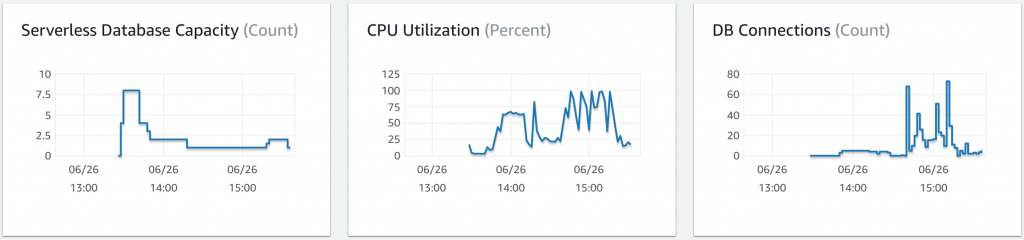
The way the downloader works is that there’s a module called Downloader which scrapes data from BGG. It passes it to a module called Inside (because it is inside my VPC) which writes it to the database. The database is quite small because it’s (supposed to be) the most expensive component of the system. But what seems to happen is that all of the files being downloaded come at approximately the same time, and sometimes the database gets overwhelmed and the update fails. So Inside fails, it tells Downloader it failed, and Downloader says “no problem I will try again soon.” But when it tries again the problem is still happening, so a whole lot of computing happens (which costs me $$) for no result.
This is coincidentally one of the ways that the system at work was failing – with the hammering from the customers, the site was maybe 50% busier than it had ever been before, so most bits were doing 50% more work. But occasionally there would be some interaction where a task that should take a second would blow out to an hour – I suspect some sort of database contention, but I don’t know how to prove that.
At work I seem to have solved the last problem by adding an index to a seemingly unrelated table – something that was taking 5 seconds now takes 0.1 second, and incidentally fixes the unexplained hour-long blowouts in another part of the system. As a perfectionist I am not happy with my understanding of the system, but as a human being I’m pretty fucking stoked that I stopped shit breaking. So I have a chance to relax a bit.
The PLAN is that in my relaxation time I can work on Extended Stats. But as explained, the problems with Extended Stats, and most of the technologies, are the same as work. So it’s not the thing I could do that relaxes me the most… but here I am writing a blog to show you that I am still on the project. Work owes me a bunch of days off and I intend to claim some.
So the plan with Extended Stats is to replace the Inside module with a module called InsideQueue. AWS has a service called SQS – simple queueing service – where you can put data items onto a queue with one program and take them off with another. The Downloader will put its data from BGG onto a queue, and InsideQueue will take them off one by one and make the database changes. This is a pattern we use at work which works well, as long as we separate the important short tasks from the slow ones.
So apart from procrastinating and writing a blog post (oops, I mean “communicating with the users”) that is what I’m doing today. I apologise to all of the people waiting to be added to the site – it’s kinda futile to do that while the downloader’s not working anyway. OK, let’s see if I can make this work…