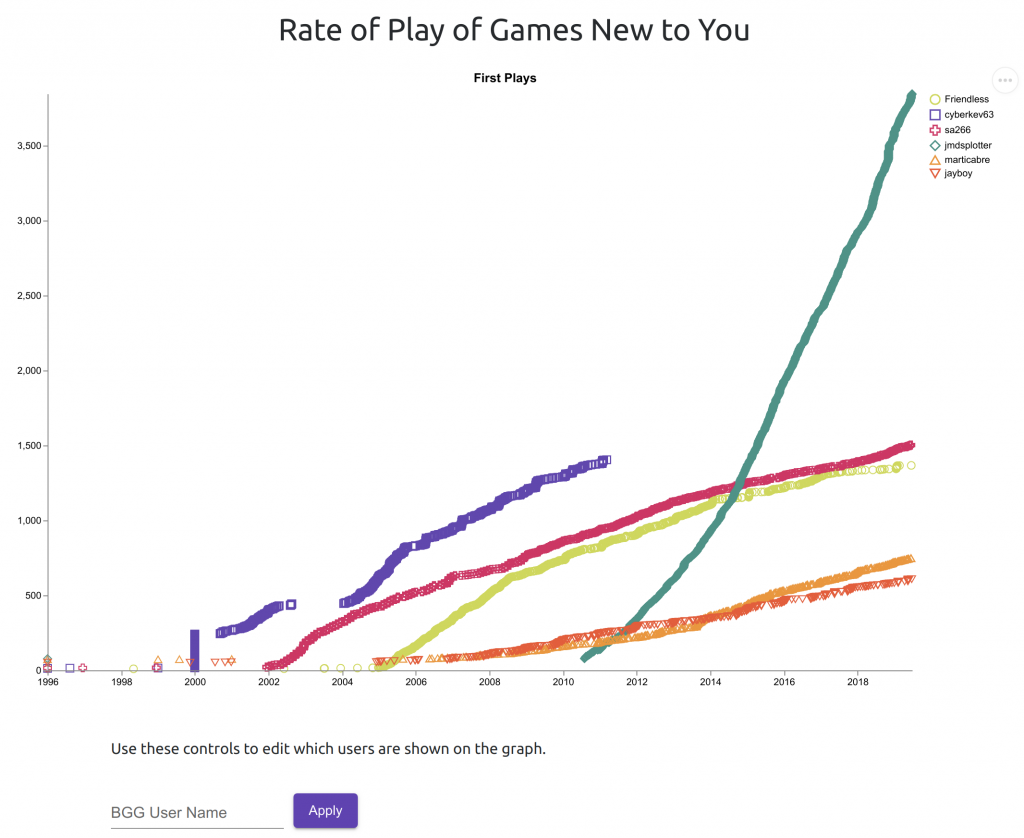
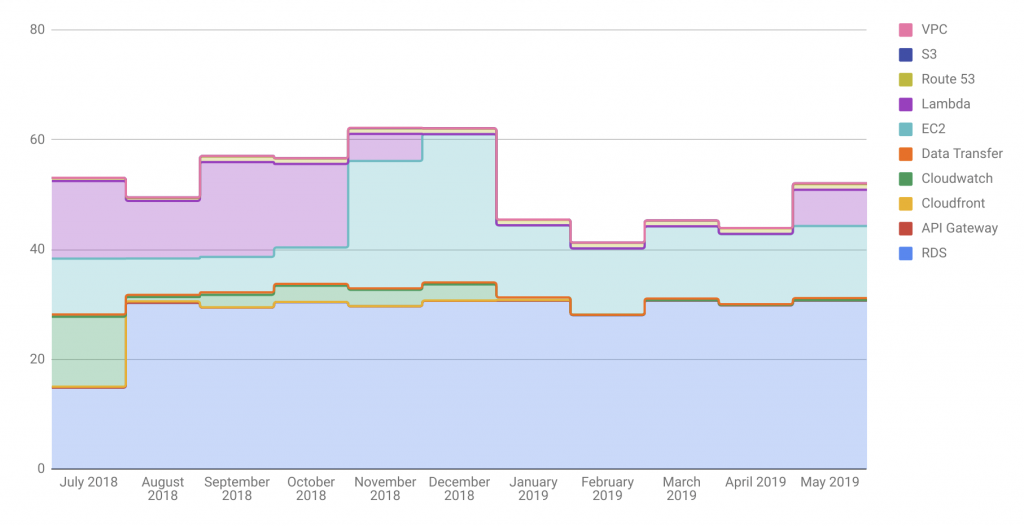
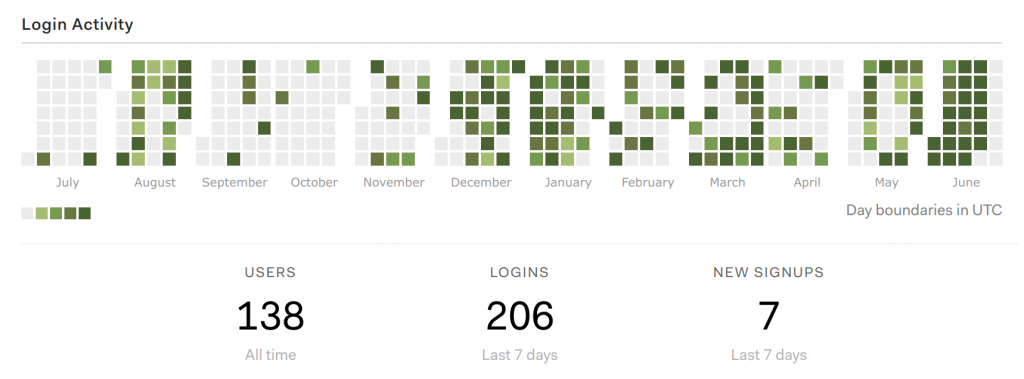
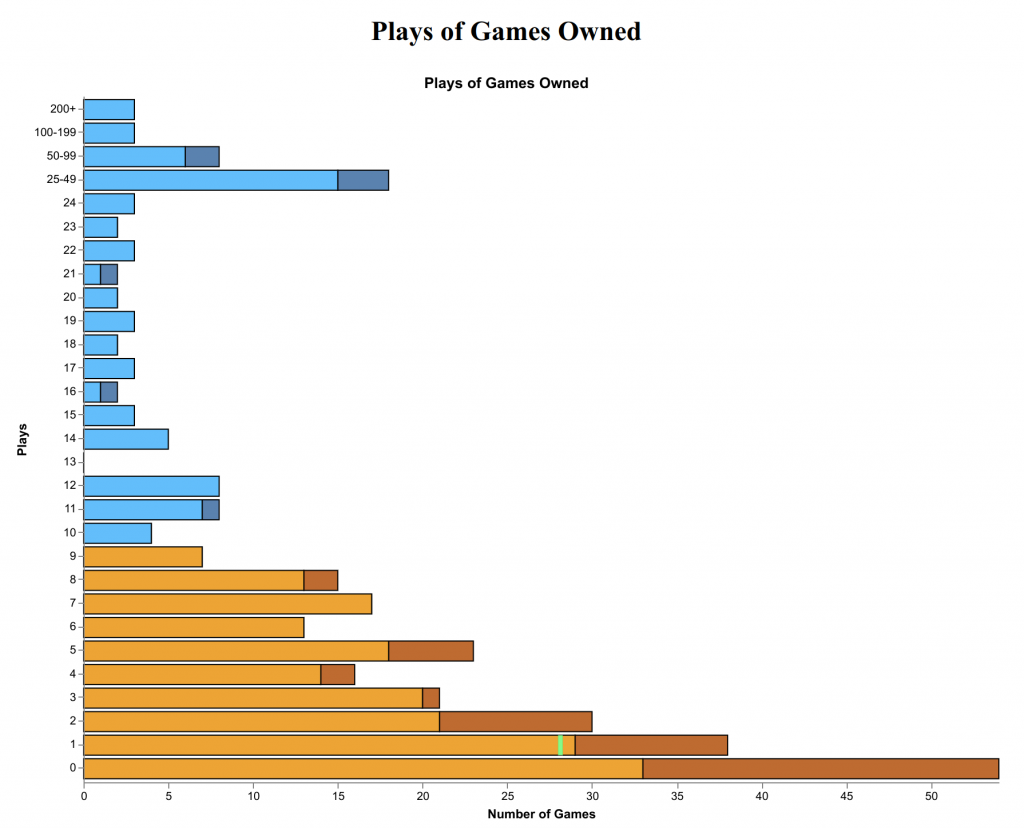
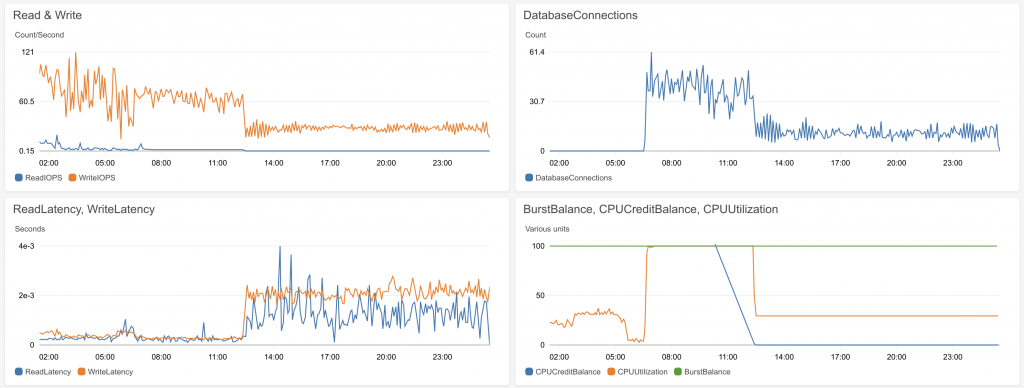
I blogged a couple of weeks ago about my unsatisfying experience with React. I then got to pondering what I might do with React – I liked the navigation bar that I did, and so would like to continue using React for little bits of the page outside of the main applications, like the login button.
One of my goals with the system design has been to allow other developers to write pages, by which I mean the data presentation components. Angular and React usually call those things Single Page Applications (SPAs), by which they mean you don’t keep loading new HTML pages as you click around and do stuff. What they don’t typically mention is that because SPAs don’t play well with each other they tend to be You Must Write The Whole Page Using This And No Other JavaScript Applications.
If you try to put two Angular applications on the same page, they both try to install something called zone.js, which can only be installed once. So don’t put two Angular apps on the same page.
If you try to put two React apps on the same page, they both include React libraries. And if the two apps use different versions of the React libraries, then they interfere in unpredictable ways.
The way I discovered this was I rewrote the login button in React, and put it on the same page as the navigation bar. Due to quirks of fate, each used a different version of the React library, and it didn’t work. I consulted the React guys on Reddit, and they suggested I was doing it wrong, and that I should just write the whole page in React. I didn’t want to do that, because what if some other developer wants to write a data presentation component in React? Then they would need to match the React version of the hosting page. I am an extremely stubborn person when it comes to implementing a plan, so that was not going to happen.
I continued thinking about this, and about how the navigation bar didn’t really need React at all, and I had the idea of server-side rendering. SSR is when you run the JavaScript to generate HTML before sending the page out – so you send more HTML and less JavaScript. And there’s a technology called GatsbyJS which is designed specially for writing server-rendered sites in React, so I decided to give it a go. (I also tried one called NextJS but I did not like where that was going.)
Previously, the HTML pages, e.g. index.html, rankings.html, were written using a technology called Mustache, which is just a template language. If I wanted the navigation bar I would just put in {{> navbar}}. See how those curly brackets look like mustaches? That’s the joke.
So to convert to Gatsby I pretty much had to convert my HTML to React JSX, which is basically JavaScript code which looks like XML. That wasn’t so hard. But then Gatsby gets miffed if it doesn’t own the whole world, and if you want to refer to things which are outside the Gatsby world you have to use a feature called dangerouslysetinnerhtml. Being the daredevil and mule-headed SOB that I am, I did that, and pretty much got the site being generated from Gatsby.
There was a hiccup when I generated the Gatsby site – remember the point of server-side rendering is to do the JavaScript on the server, not in the browser – and Gatsby stuffed a whole bunch of its own JavaScript into the page to preload pages it thought the user might go to next. I was pretty annoyed by that – if I want JavaScript in my pages, I’ll put it there! Luckily Gatsby has decent facilities for hacking the result, so I figured out how to tell it to throw away all of that JavaScript I didn’t ask for. I do resent always ending up working on the most advanced topics on my first day with a new technology.
And that was when my IDE (my smart code editor) stopped coping. I had most of Extended Stats in one github repository. So I would open the project in the IDE (I use Webstorm for this) and it would try to find all my code and figure out what bits referred to what other bits, which is very handy when you want to know whether something is used or not. However with 3 separate CloudFormation stacks for Lambdas, Gatsby, and a dozen Angular applications, it would get confused sorting all that out. As far as I could tell it would take an hour to reindex the code, and during that time it wouldn’t allow me to paste more code in. That was unacceptable , so I decided to move the client module out into another repository and project.
Great, except that something had sabotaged the Gatsby project so that Github ignored it. Github is the cloud site where I store my code, and if my code’s not there it’s only a hard drive crash away from ceasing to exist altogether. So I had to convince Github to store the Gatsby code. I never did figure out what was going on, but I did copy the code to a different place and pretended it was new, and that worked.
And then after that worked, I could get the login button working, and then I could build a replacement site using Gatsby. The login button is tricky, because it does require JavaScript to work, and I can’t write that JavaScript in Angular or React, it has to be what they call VanillaJS. But that’s OK, I had a few versions of that code lying around already, so I just copied it into React’s dangerouslysetinnerhtml drama. And now it all works, mostly!
I deployed that version this morning, and it just made the daily sync with the CDN, so the Gatsby version of the site went live a short time ago. I just noticed that the user page is calling itself the Selector Test page, which I will have to fix. But overall I’m happy with this experiment. I still have to delete a few things that have become obsolete, like older versions of the login button and the nav bar, and I will fix up the CSS so the pages don’t look so cluttered and jumbled, but I feel this solution is better than the Mustache one. And I guess I can now really claim to have some experience with React.