I spent most of yesterday working on login, AGAIN. I think that’s the fourth full day I’ve put into that subsystem. Except for the few minutes I spent to stick the navbar onto all of the pages. It’s ugly, but it’s kind of a fundamental component as it helps users discover what pages there are on the site.
One of the entries in the navbar is “Data Protection”. This is not a very interesting topic, but thanks to the European Union’s General Data Protection Regulations, it’s something I probably need to deal with at some point. Having contemplated retrofitting GDPR compliance to the website at work (which is unnecessary because we only conduct business in Australia), I decided that the best way to deal with GDPR would be head-on up-front.
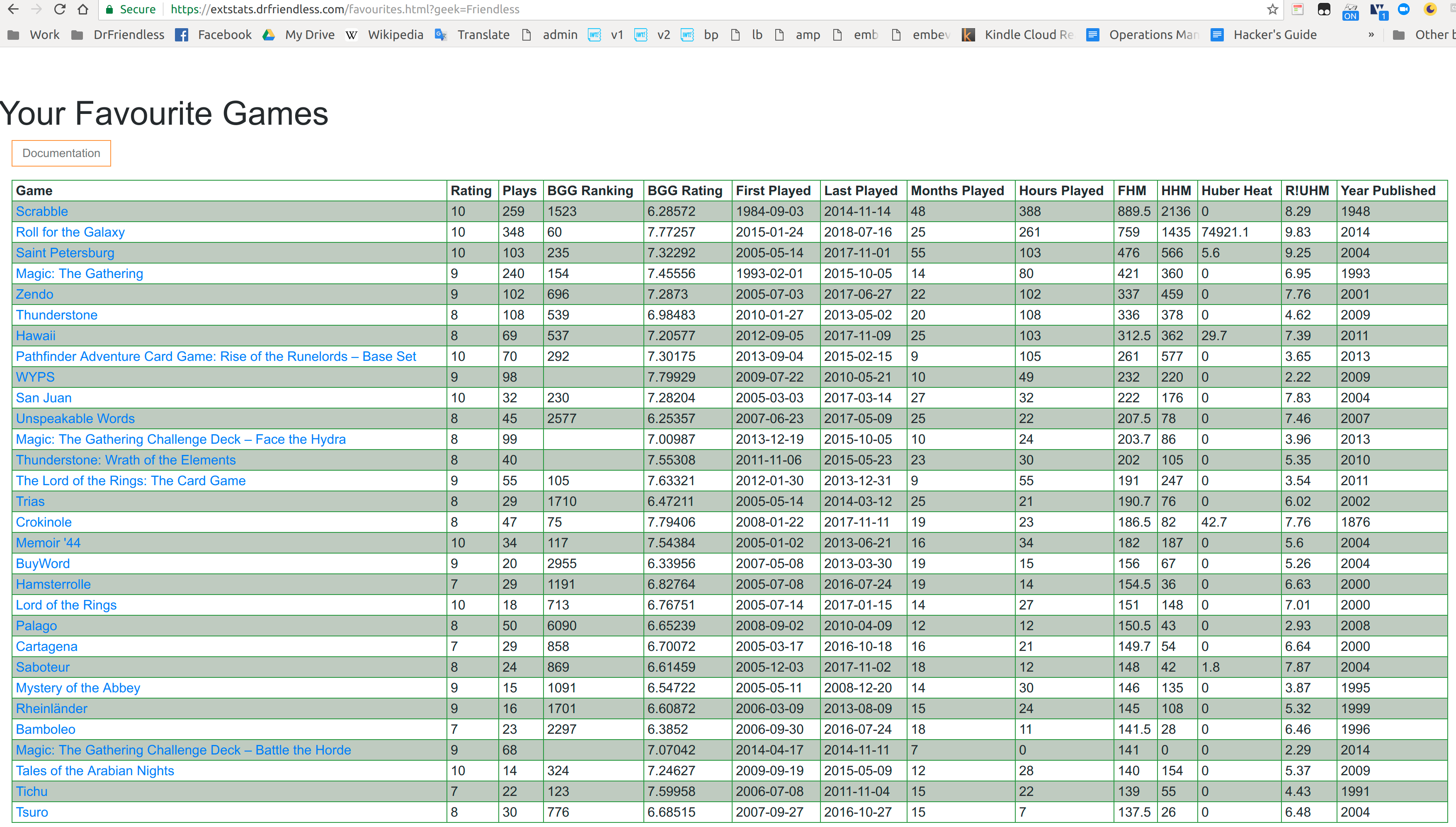
This is why the only thing on the User page (https://extstats.drfriendless.com/user.html) is a JSON dump of the data I store about a user. I was starting work on configuring user options, but I got bored and will have to spend probably another day on that. The sorts of things I would add first would be:
- screen display name as other users see it
- whether you consent to have your personal data shared with advertisers
- what your BGG username is
- in fact, what your BGG usernames ARE.
That suggests a few things about the future of the site. First of all, advertising. Yes, there will be some, unless I make sufficient money to fund the site some other way. In fact I tried to turn ads on already but Google refused for unexplained reasons. One day I’ll try again.
Secondly, other users seeing your screen display name. I have to admit I don’t know exactly where that’s going, but maybe one day add the ability to play games online. I’m very interested in coding games, but I guess I had better get the site going first.
Oh yeah, and your BGG user names. Some people manage multiple BGG accounts – theirs and their spouse, and their games group. So I would like to make switching between those accounts easy. Maybe I will also add geekbuddies, so that you can easily compare yourself to your buddies, or treat them as a group, or something. I did once develop an app to help decide what you and a bunch of friends might like to play, and I would love to bring that onto the new site.
The missing page in all of this is the Geek page. The Geek page will be the central place for the site’s data about a particular BGG user. Naively, I expect it to be similar to the pages in the old site where a bunch of tables and graphs are presented. I don’t think that’s practical though, for several reasons.
The web technology that I’m using to write the interactive parts of the pages, Angular, is very clever. However the one thing it can’t do is play nice with other Angular applications on the same page. Even on a page like the front page or the user page, the application on the page and the login button interfere with each other. I haven’t seen any particular errors related to that, but I don’t want to take any risks. So I need to figure out some solution to that – maybe isolating them from each other in IFRAMEs, or packaging them as Angular Elements (which don’t work very well yet).
Another argument against the pages full of features like the old site has, is that that’s a pretty archaic way to do it. All of the graphs there are generated on the server side, and the PNG data is sent to the client. As JavaScript can do some very cool stuff these, the modern way is to use the data that was loaded from the server and draw the graphs in the browser. In fact, see my next post which I haven’t written yet for more details.
This suggests that the new site will be substantially different from the old site. With selectors being more shareable, pages being much more suited to interactivity, and fancy things like graphs being easier to do, I am guessing it will be a lot more interactive and encourage exploration. What sort of experience that adds up to remains to be seen.
Finally, as I write this, the downloader is struggling to complete the download of the plays data. By struggling, I mean there are 16 files left to process out of about 300000, and those seem to be broken. So I’ll go fix that and then write another very exciting blog post.